在GDC2017 《守望先锋》Replay System的分享会上,来自暴雪的Tim Ford介绍了《守望先锋》服务器团队开发工程师Phil Orwig,分享了回放系统(Replay System)的设计。
大家好, 请关闭手机或者至少调至静音状态,我们准备开始了。
欢迎来到“守望先锋”(下文统称Overwatch) 回放技术分享,今天的内容包括阵亡镜头、全场最佳和亮眼表现。我是Phil Orwig,是Overwatch服务器团队开发工程师。
那么(下面)我们将深入到Overwatch里,这是暴雪在第一人称射击游戏领域的处女作。它是一个团队合作竞技游戏,主要特色是各个身怀绝技的英雄。
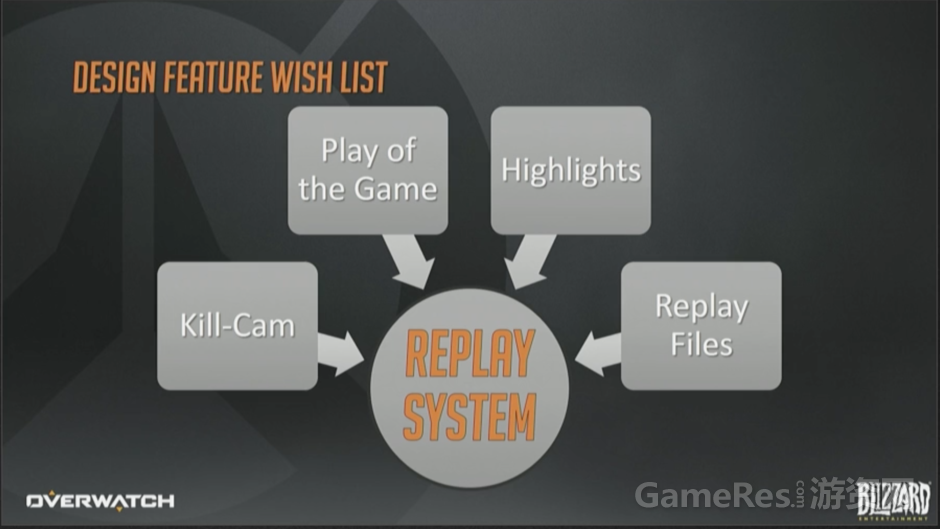
这次分享会覆盖回放系统(Replay System)的设计目标,深入架构与实现的细节,以及深度打磨的过程。同时,还会讨论我们遇到的挑战以及对应做出的折衷,最后会展望一下回放系统未来的目标。
那么回放系统的概要设计(high level design)目标是什么呢?
这次分享的标题就预示着必须给出答案,对吧?概要需求是创建一个单一的中央系统,能够支持阵亡镜头、全场最佳和亮眼表现,除此之外我们还特别需要能够生成录像文件,在开发期间可以用来做内部调试。
下面开始深入介绍每个议题。
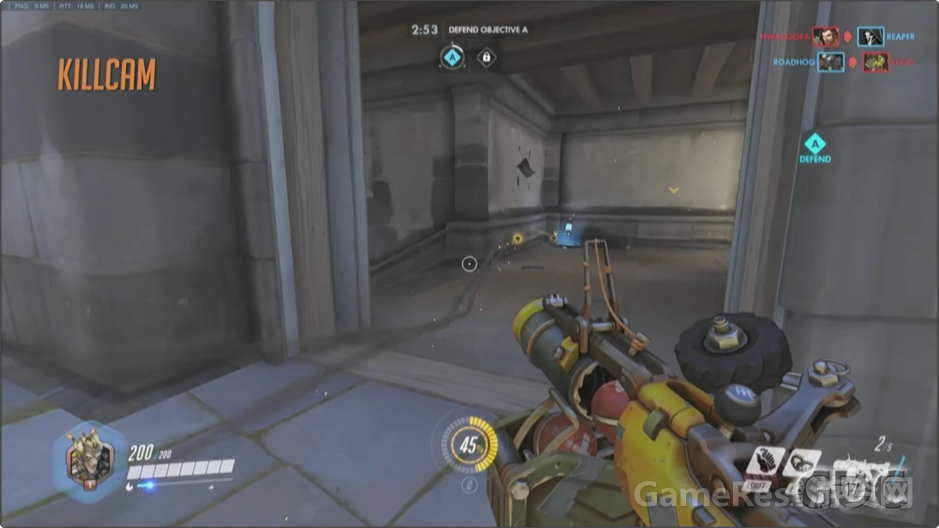
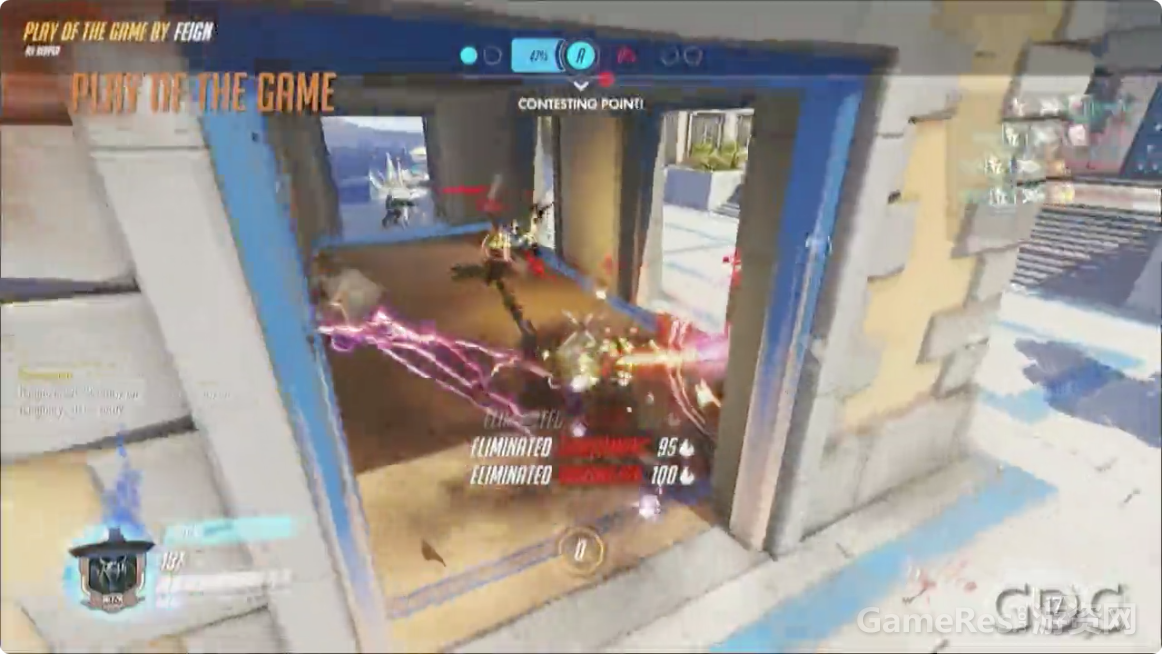
每次玩家死亡时,游戏里就会显示临死前几秒钟的――大部分情况是以凶手(killer)视角来看的――死因及死亡过程。阵亡镜头可以帮助玩家理解他们是怎么死的,以及为什么会死,有一定的教学作用。
上面展示的视频例子(狂鼠被半藏杀死的例子)中,可以看到死亡过程中的几个关键节点,玩家死亡时有3件值得注意的事:玩家尸体布偶化(ragdoll,也叫布娃娃,专用术语,全称Ragdoll physics,是用在电子游戏的物理引擎中代替传统静态动画的可变性角色动画系统),方便判断死亡方式(译注:估计说的是炸死、摔死还是射死等);游戏镜头朝向凶手;凶手轮廓描边,即使隔着墙也可以看见,从而使你查看得更加清楚(译注:这一点在视频中没有得到展示)。
我们会以淡入的方式进入阵亡镜头,展示死前一段时间以及死后几秒钟的画面。你能看见自己的尸体布偶,然后明白自己是怎么死的。
我们希望阵亡镜头可以让你学到东西并提高技巧,但不是每个玩家都能享受这个目睹自己死亡的过程。我个人就可以证明,看着自己的英雄一次次倒下带来的那种无力感,如果持续体验这个过程,慢慢地会感觉这简直是黑色幽默(macabre sense of humor)。
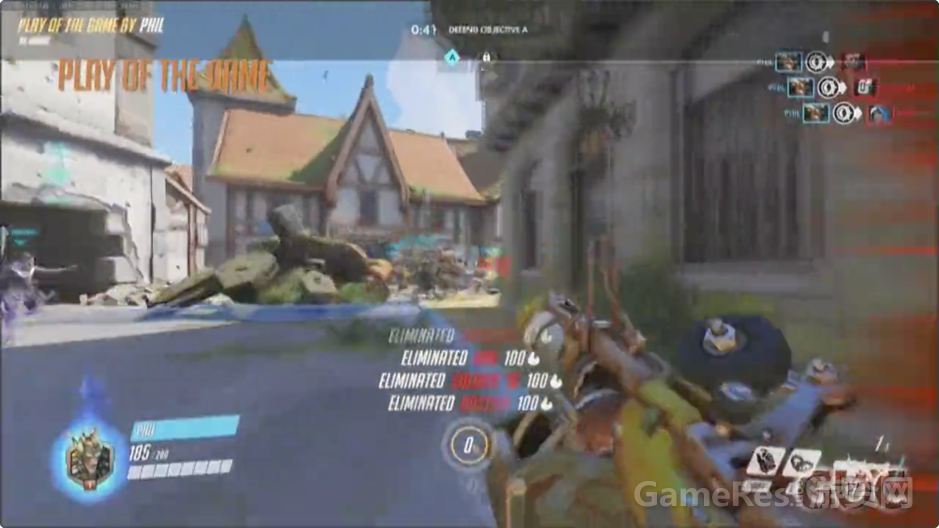
另一方面,“全场最佳”是个赛后集会点,在此你和伙伴们可以庆祝共同创造的精彩游戏体验,也是一个共同分享的伟大时刻。它可以激励玩家为了得到最佳而拼尽全力,证明自己,同时炫耀自己独有的个性化英雄形象。
在本部分结束前,一起看下这个过程,我们会从队伍胜利播报开始,切到玩家英雄特写,最后过渡到精彩的团队合作与高超技巧的展示。
有点技术问题,稍等一下。。。好了,请欣赏我的“全场最佳”
嘿嘿,我没那么厉害啦,其实对面都是机器人 (众笑)(译注:视频中Phil拿了个4杀)。
玩家如果觉得自己可能能成最佳,他们就会提前卖弄,像下面这样。
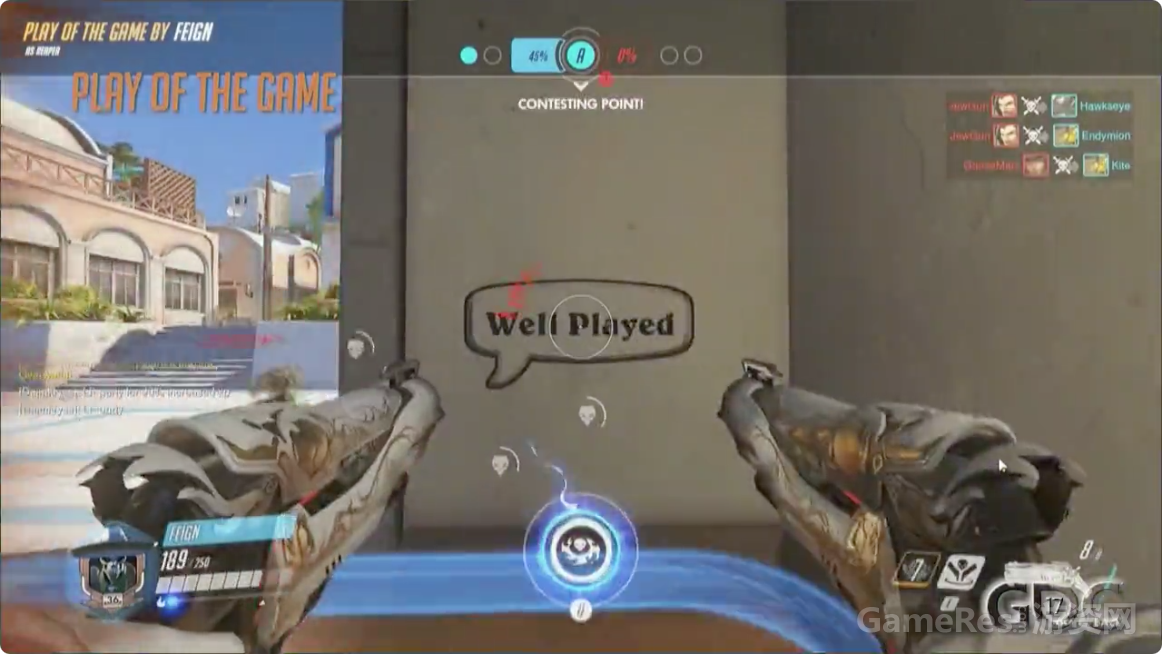
视频中的死神本来已经被查莉娅的大招“重力喷涌”困住了,但是他通过幽灵形态成功逃脱,此时他的大招能量刚好充满。他转身放了个喷漆在墙上,紧接着开大,人挡杀人,佛挡杀佛 。
这里最值得注意到就是,这个玩家如此自信以至于在开大前就喷了个漆:Well Played(译注,守望先锋中,时机把握得当,这个行为就会被全场最佳一起记录下来,是高手炫耀的一种常见方式)。那就好像是说:我这次肯定要拿最佳!
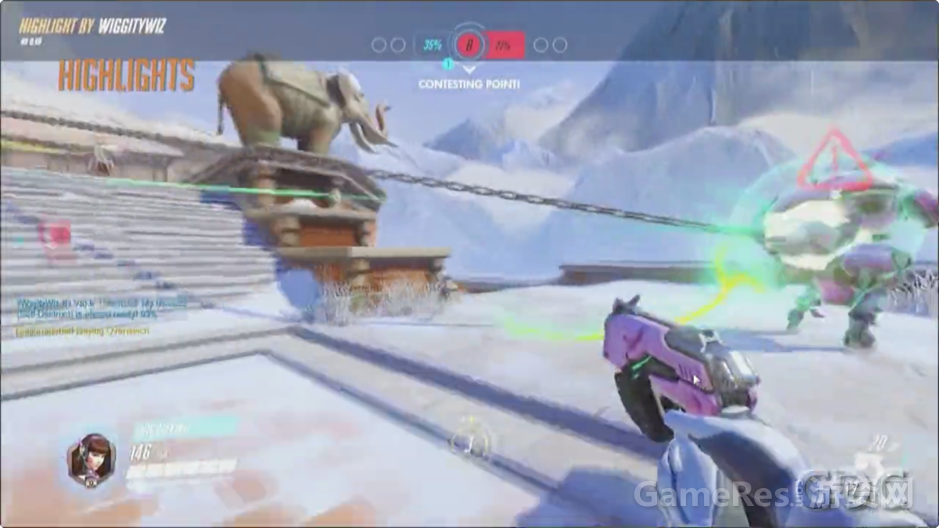
“全场最佳”带来了很多适于分享的话题,但是假如你没拿到最佳呢?或者虽然你拿到了但是恰好没有合适的录像软件记录这一切呢?对此,我们的解决方案就是“亮眼表现”。12个玩家里面,只有1个人能拿到最佳,而所有人都会得到“亮眼表现”(highlights),这个可以在游戏大厅入口处播放。有了这个功能,玩家可以更容易地捕捉到自己的炫酷表现,并分享给好友。
这个例子中亮眼表现的作用,与其说是炫耀技巧,还不如说是用来搞笑。你可以看见一个路霸失手勾到了D.VA的自爆机甲,结果全队被炸上西天,太惨了(众笑)。
当然,玩家现在还不能自由地使用回放功能,主要还是给游戏内部开发过程在用,我们也有个快捷键可以保存过去30秒钟的回放数据,并保存到硬盘。如果你的电脑上刚好有Shadow Player之类的DVR设备, 也可以保存录像。
可以想象得到,有了这两大武器,以往很难重现、定位的bug,现在都可以很容易地隔离并修复了。除此之外,性能测试做起来也更加方便了。不需要凑齐12个人,开发者就可以随意修改代码并分析测量性能数据了。
顺便说一句,我们想要凑齐12个人其实并不难,无论何时你只需喊一句:跑下版本呗!马上就能满员甚至还有富余(众笑)。不过这事关开发效率问题,不能每次都喊人帮忙。
开发期间,我们还可以把录像文件连同特制的客户端一起发给合作的硬件厂商(first party vendors),帮他们诊断特定平台下的硬件驱动bug和性能问题。
闲话少说,咱们接着讲网络同步,主要包括设计回放系统的常规模型,以及如何交互。
回放系统不可避免地要受限于模拟(simulation,游戏逻辑 渲染)模块和网络模块。
确定性帧同步(deterministic lockstep),常用于竞速游戏或者星际争霸2、魔兽争霸2这样的即时战略游戏;
快照插值(snapshot interpolation),FPS经典同步模型,《Quake》最早采用,后续众多FPS在之上做了改进;
状态同步(state synchronization),有点像是快照插值的改进版,也是Overwatch所采用的。
注意我的幻灯片下方列出了一些参考文章,正是这些文章启发了我们,设计出了我们自己的同步策略:
GDC2015 Physics for Game Programmers : Networking for Physics Programmers
I Shot You First: Networking the Gameplay of HALO: REACH[David Aldridge]
The TRIBES Engine Networking Model [Mark Frohnmayer]
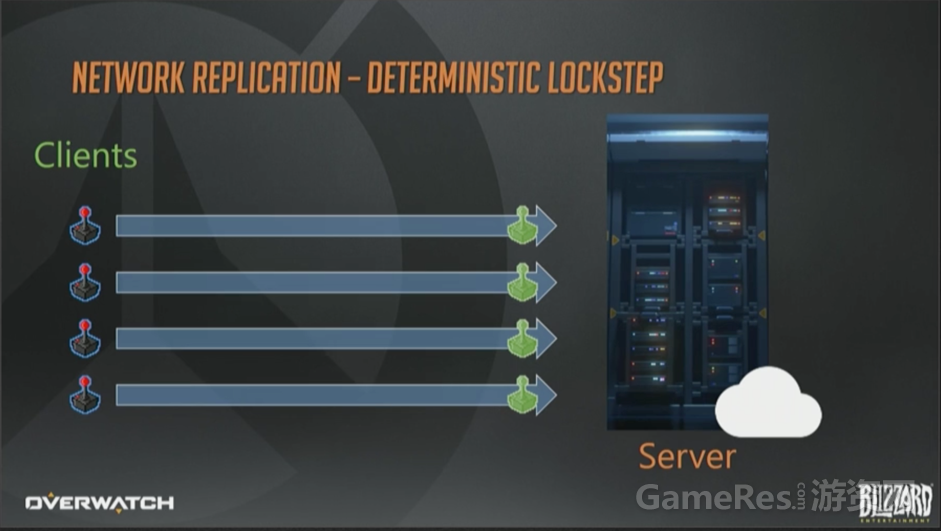
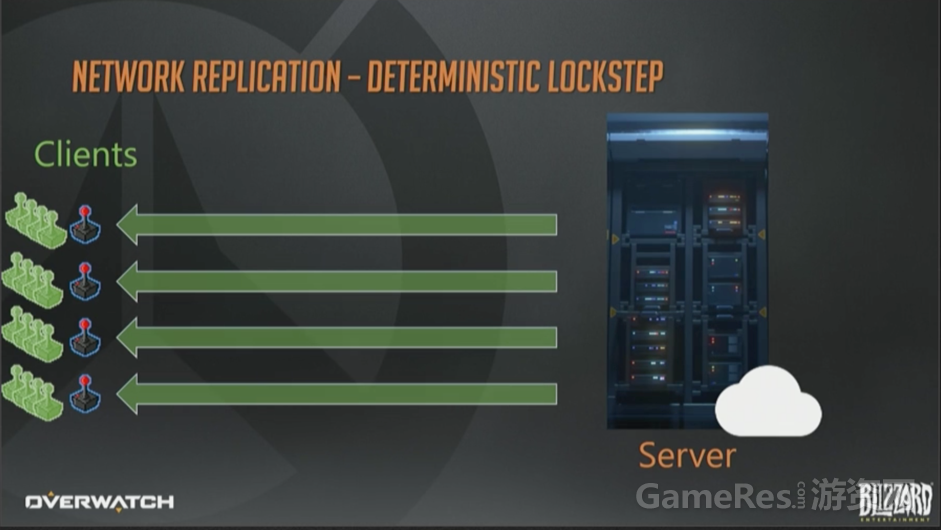
快速浏览一下这些技术。第一个是确定性帧同步,左边有4个客户端,都连接到同一个服务器上。服务器也可以由其中的一个客户端来兼任。简单起见我们假定有个专属的某某云服务器。
客户端接收玩家输入并上报给服务器,服务器在接收到全部输入以前,保持锁定当前帧。当全部客户端的输入都上报完成时,服务器才开始模拟游戏进程。
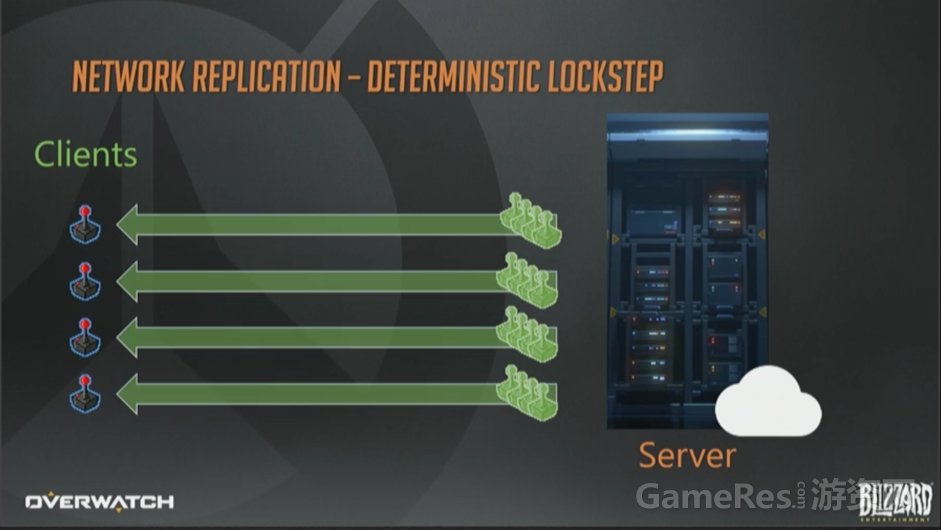
处理好全部输入以后,服务器批量打包所有指令,并转发给全部客户端。
然后客户端基于刚刚收到的转发指令,开始各自模拟游戏过程。代码处理得当的话,每个客户端都会得到相同的结果,看上去很美妙。
基于帧同步实现一个回放系统很方便,只需要记录整个输入流即可实现回放。而且输入通常很容易压缩,所以数据量也不大。
确定性帧同步,虽然架构简单,但是也有一些缺陷。它的模拟过程需要严格一致,同一帧内,相同的输入集合在每个客户端必须产生同样的输出才行。
如果做不到这一点,客户端之间就会产生不同步,会对当前处于何种状态各执一词。例如对浮点数依赖程度很高,而浮点数运算很难做到严格一致,尤其在不同的平台架构下更是如此。 一个简单的打印驱动失灵,就能在中断控制器上改掉浮点数精度设置,从而使模拟过程偏离轨道。而且这一点的确会发生。
维护一个确定性的模拟过程,除了代码逻辑上的工作以外,还有一个问题就是多玩家联网时产生的。
“等待全部玩家的输入”意味着,任何一个停滞的玩家都会破坏模拟过程的及时性。游戏里玩家数量越多,这个风险越高。简单计算一下,假设一个5分钟时间的游戏,每个玩家卡顿的概率是2%,4个玩家就会有8%的可能性,玩家多达12个时,已经是22%了。
我本应该画个图表来说明这一切的。
上述缺陷都是可以克服的。 通过遵守合适的编程规范就可以开发出并维护一个确定性模拟系统的,我们开发过很多这样的游戏,这样做绝对可行。 或者可以耍点小聪明来隐藏缺失玩家输入引起的卡顿,例如你可以用倒带法(rewind)重新模拟或者维护一个预测(predict)窗口。
Overwatch最终没有选择确定性帧同步方案,原因如下:首先,我们不希望程序员和策划的因为偶现的不确定性而产生心理负担;除此之外,要支持中途加入游戏也不简单。模拟操作本身就已经很耗了,如果5分钟的游戏过程,每次都需要重头开始模拟的话,计算量太大。
最后,实现一个阵亡镜头也会很困难,因为需要客户端快照以及快播机制。按理说如果游戏支持录像文件的话,快播自然就能做到,不过Overwatch并没有这一点。
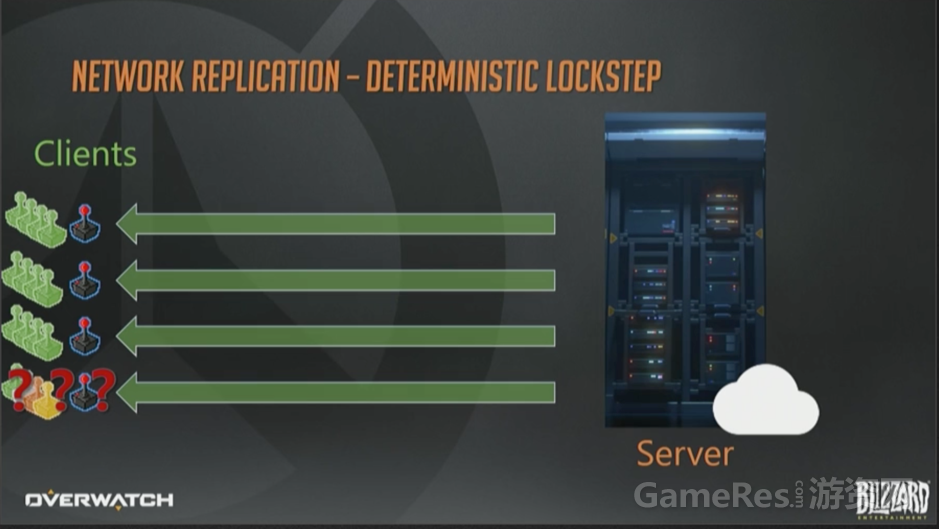
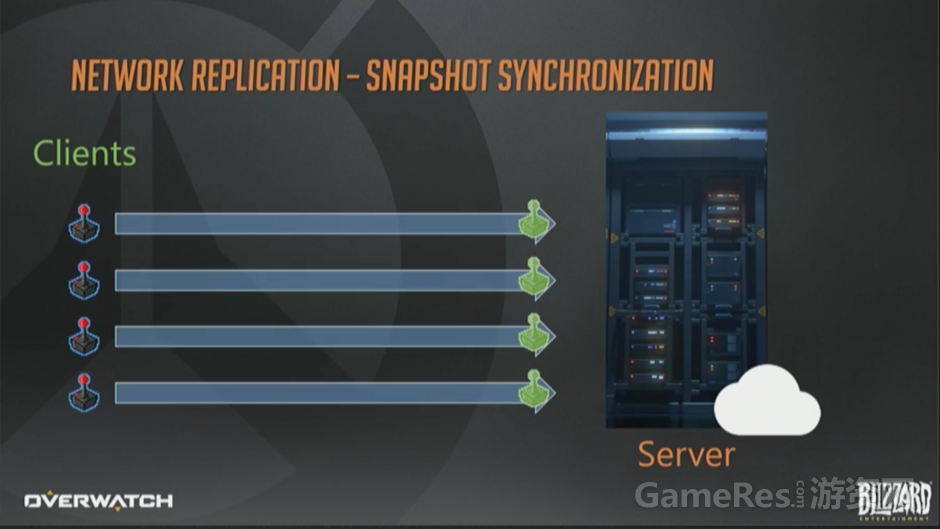
那么下一个选项就是“快照同步”了,与确定性帧同步相类似,也是客户端接受玩家输入然后上报给服务器。然而,这个模型里的服务器是可以忽略某个玩家输入缺失而继续向前模拟的。
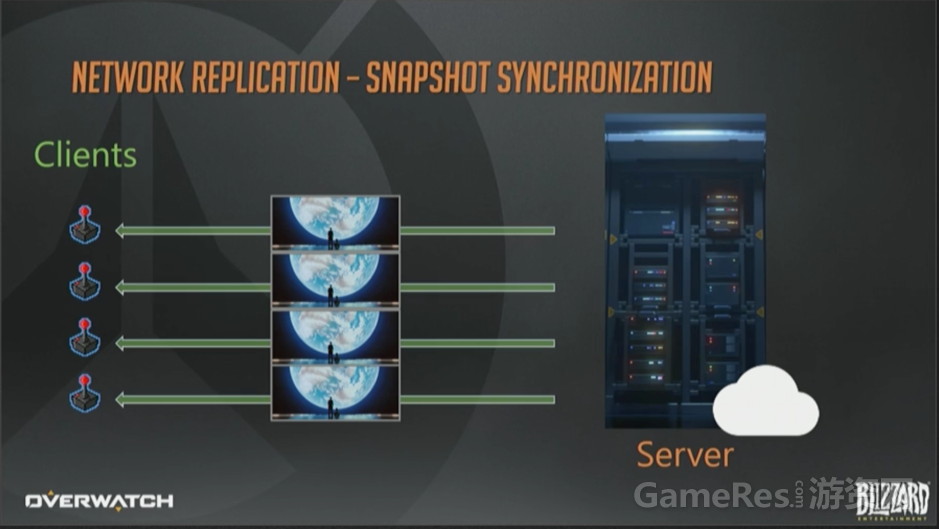
这里不会转发输入操作给全体客户端,取而代之的是服务器模拟游戏世界,不停地生成整个世界状态的瞬时快照。
然后服务器会把快照下发给客户端。客户端根据这些快照来更新各自的世界状态,通常会用“插值”方法在两个相邻的快照间做平滑(译注,关于插值,可以参考Source引擎,解释的比较权威)。
这种方式运作良好,概念也很简单,同时避免了帧同步模型中的确定性和卡顿问题。事实上,稍加改造,再结合一些压缩,就能得到一个比较可靠地模型了。
差异计算过程比较耗费资源,你可以分摊快照成本或者“增量”(Delta,下文中会多次出现,并直接用英文单词)压缩,这样对于多个客户端来说,只需要处理一次就好了。
如果你担心有人作弊,你就需要维护一些客户端不应该看见的对象的实时数据,然后只下发客户端能看见的东西。
基于快照同步实现回放系统的话,十分简便。从一个完整世界状态开始,更新每帧时添加差异就好了。广义上讲,这个方案就是依赖新技术的游戏客户端如何播放录像文件的问题。客户端要做的仅仅是把网络游戏数据序列化到硬盘上。
这套架构实现阵亡镜头同样很简单。 你已经有全量的快照了,对吧?所以只需要维护一个环形缓冲区,保存过去时间点到当前时间之间的世界状态历史,然后重播就行了。注意到我把这里快照(图片)的大小做成不同(译注:指的是上图中Replay Stream线上的4副图)的,你可以图片大近似想象成每一帧的序列化数据尺寸。有一些帧变化的少,所以尺寸就小。
这个例子里,我同样使用了不同尺寸的管道(代表数据量的多少)。快照尺寸就相当于快照同步模型的阿喀琉斯之踵,它限制了在每一帧内,世界状态变化的程度和次数。需要同步的东西越多,初始快照尺寸就越大。帧与帧之间变化越多,Delta就越大。变化越多意味着需要的比特位就越多,而比特位需要消耗宝贵的带宽资源。
对于一个高频互动的游戏,如果想要在低带宽环境下正常运作,最终能依靠的就只剩几种主流的同步模式了。
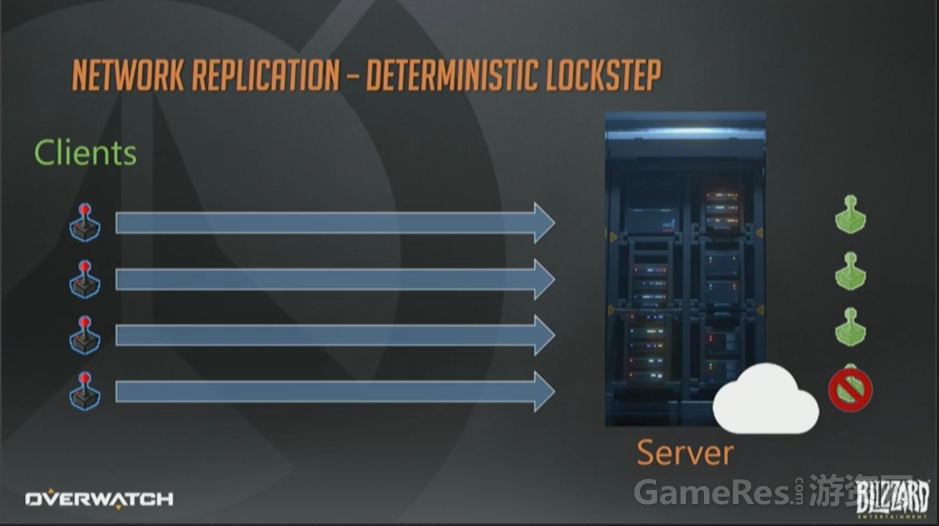
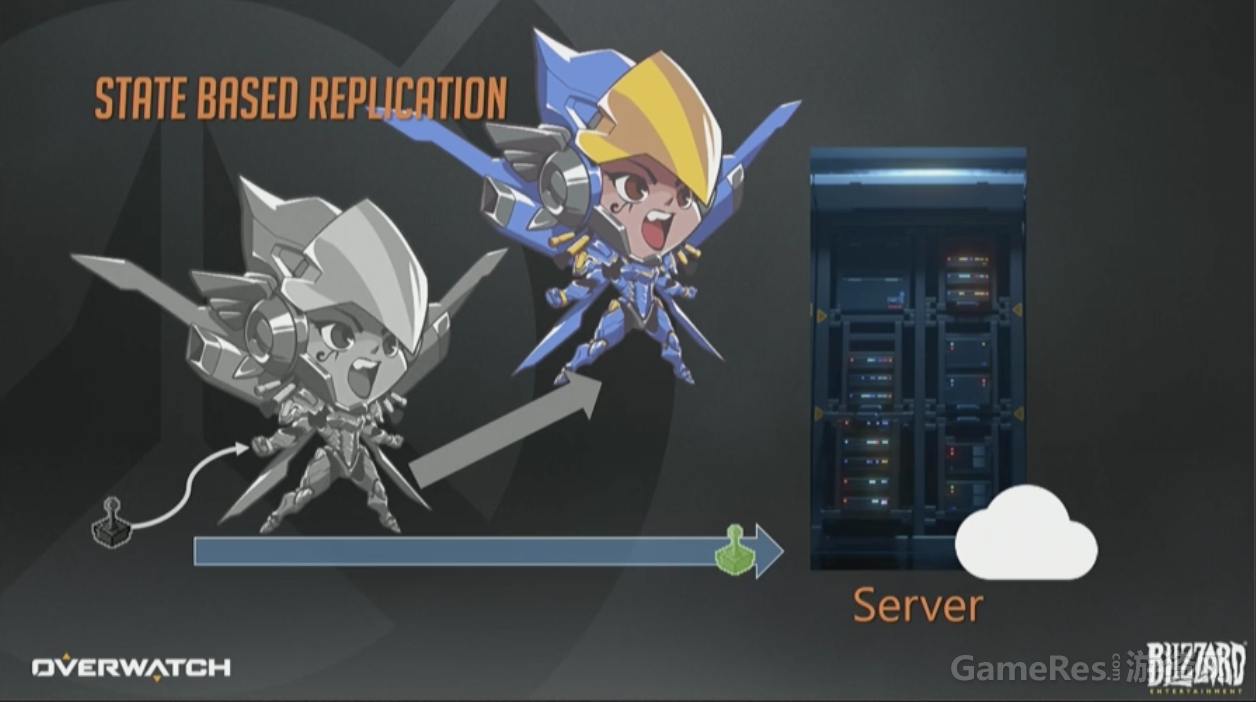
基于状态的同步。 这一页幻灯片与之前的一模一样,客户端上报输入,服务器执行模拟。
与快照同步模型相反,服务器不会为全体客户端生成单一更新,而是给每个玩家发送纯手工定制、公平贸易换来的、原生态的数据包(众笑)。
那么,当我们谈论“世界状态”(world state)时,是在谈论什么呢?
我想说的是,任何用来表达游戏世界所需的必要状态。可以想象一个代表个体位移、旋转、血量、动画参数和武器发射状态等等的分类数据表。在快照同步模型中,客户端会收到全部状态数据并“原子化”执行一遍。
基于状态的序列化,会把世界快照分解成更小的、原子的数据块。因为每个客户端收到的数据都是订制的,我们可以基于客户端相关性来设置更新的优先顺序。这样就能够基于客户端的实测带宽来智能调整数据流了。
上图的例子里,有个客户端收到1个数据包同时包含了大锤和法拉的更新信息。另一个客户端则收到了2个数据包,其中1个是大锤,然后1个是法拉的信息。这里最重要的一点就是对象可以独立更新,每个客户端的数据都是分别订制的。
客户端网络状况参差不齐的情况下,这种模型就是最灵活的,不过实现起来也是最复杂的。这就是Overwatch的实现方式。
现在咱们深入了解一下Overwatch里是如何做到稳定的网络同步的,以及回放系统在这个同步范式下是如何实现的。
先介绍几个术语,Overwatch使用的是ECS架构:实体是由组件组成的,由System负责更新(译注:关于ECS请读者参考另外一篇分享:GDC2017 Overwatch Gameplay Architecture and Netcode)。
有些System是序列化过程的参与者(participants),它们负责同步游戏的某些方面(aspect)给接收者(receivers)或者复制目标(replication targets)。接受者一般就是需要接收数据的活跃玩家或者观战者(spectator)。最后,复制目标会收到关于其他实体的更新消息。
通常我会把这一切简言之为:参与者把网络相关实体数据打包并发给接收者,这些实体就叫“主体”(subject)。
顺便给我的同事们打个广告,如果你对Overwatch游戏架构、网络同步的其他方面也感兴趣的话,Tim Ford和Dan Reid的分享刚好与我的互补。他们的已经结束,可以在GDCVault.com上收看(译注:另外一篇GDC2017 Networking Scripted Weapons and Abilities in Overwatch在此)。
下面来个具体点的例子,假定你正在控制法拉(Overwatch英雄之一)你跳了一下然后飞起来准备低空轰炸,这个消息是如何发给其他玩家的呢?
当你开心地按下按钮,客户端预测就开始了,同时(译注:原文是then,但其实这个操作不需要考虑前后顺序的)把这个命令上报给服务器。
服务器收到连同你在内全部玩家的输入后,一个经过”官方批准”的模拟过程就开始了:一些实体移动了;一些英雄倒下了;抛射物爆炸了,简直就像开Party一样,美妙极了。
最终的每个变化和事件,我们统称为Delta,例如”位置变化”就是个(服务器上的)Delta。
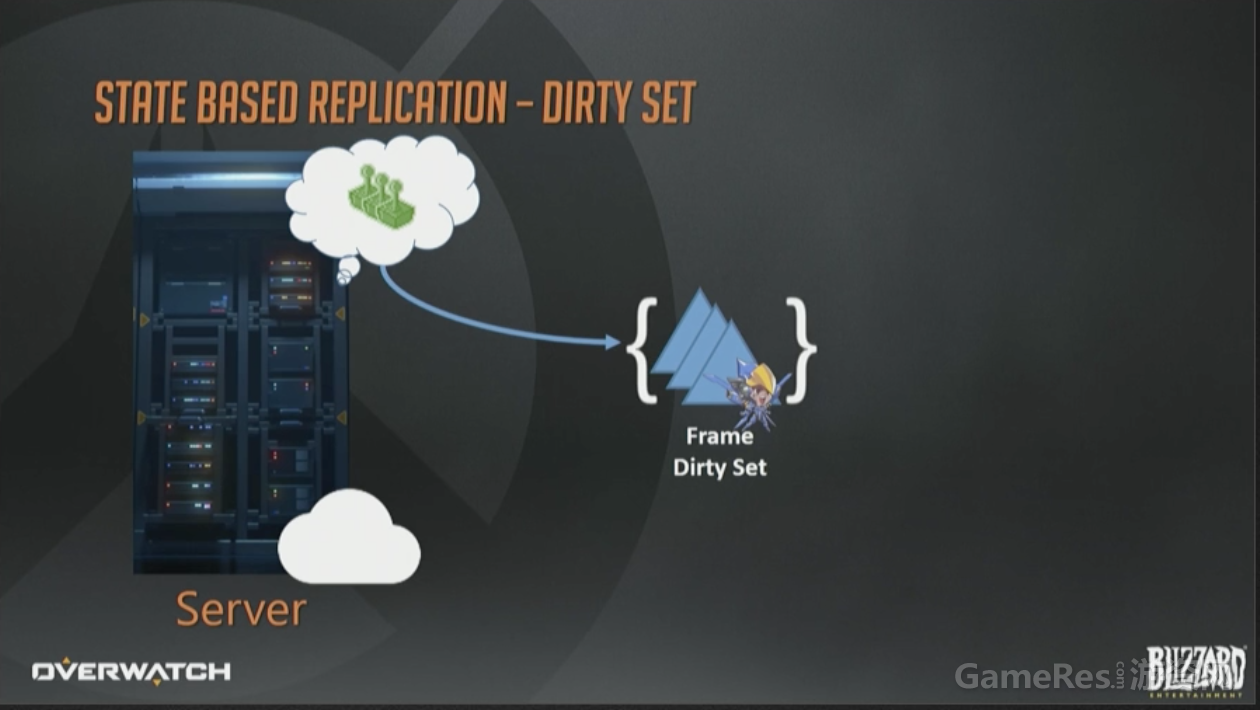
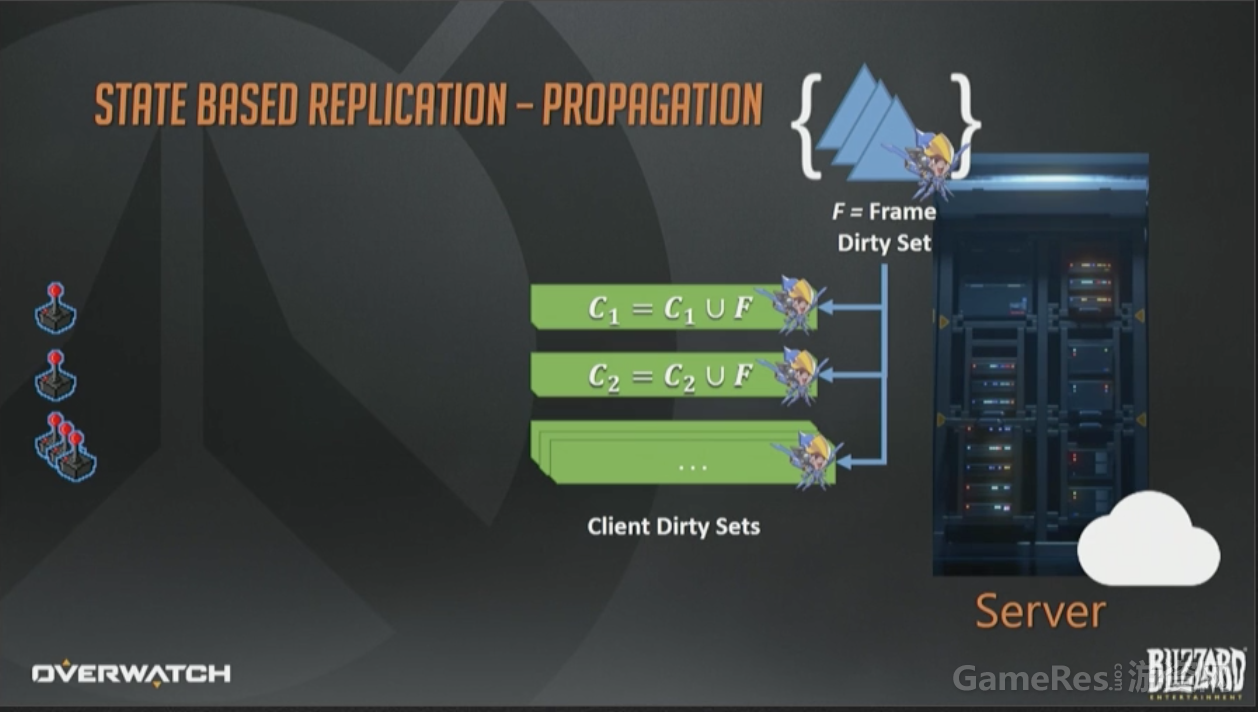
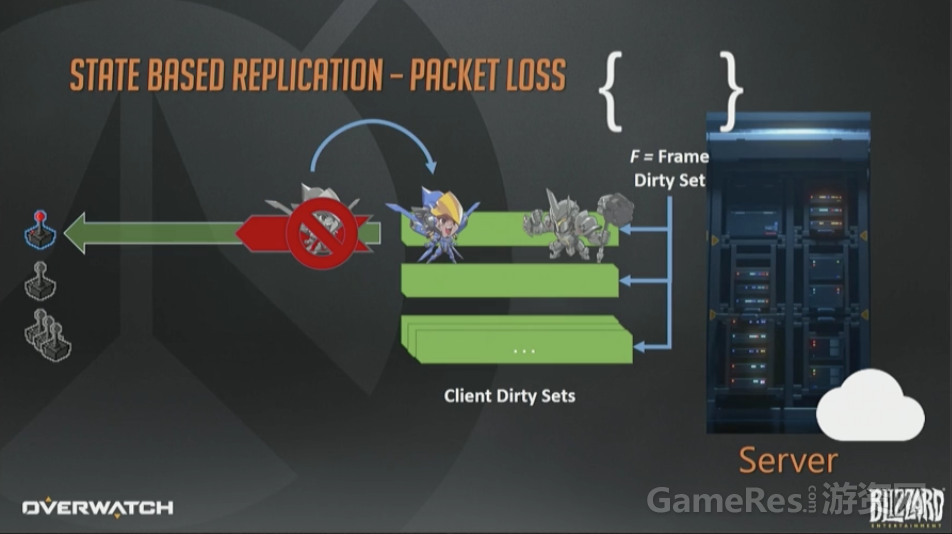
在服务器端,我们会累积所有对象状态的变化,然后保存在一个临时的“每帧脏数据集合”(per frame dirty set)里。可以简单地认为它就是个字面意义的数学概念的集合,包含所有在那一帧发生改变的实体的ID。
那如何把这些状态转发给客户端呢?我们对每个已连接的客户端也维护了一个“脏集合”(译注:应该指的是C1, C2…作者没有交代这些集合是如何生成的,不过从下文的C1=C1-P可以推测出来)。这一页幻灯片右上方的F是当前帧脏集合。每帧结束时,所有接收者的脏集合会与帧脏集F合并(还是数学上的并集概念),这样数据打包时就可以只包含那些该客户端真正需要的实体集合了。在帧结束时,这些操作都做完以后,帧的脏集会被清空,下次更新(tick)时,一切重头开始。
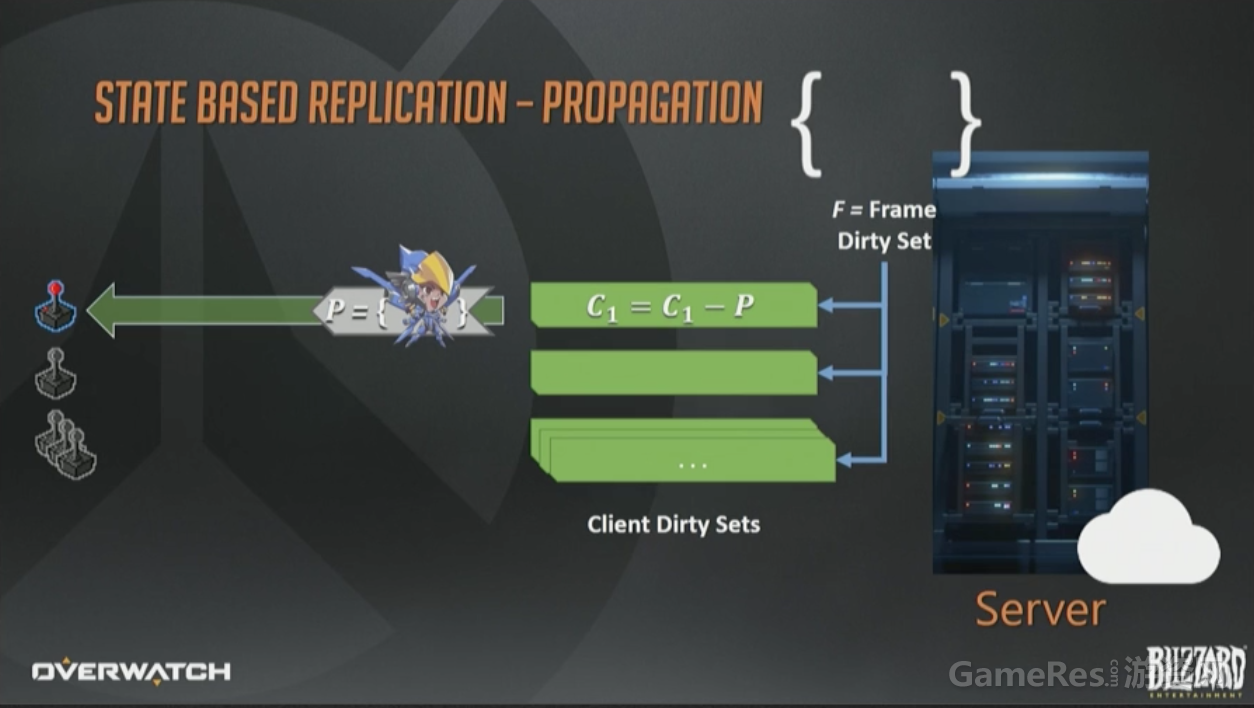
在同一个更新周期(tick)的后期,脏状态(译注:C1,C2…)会被序列化成一个数据包,通过“网线”(这个年代到处都是网线)发给接收客户端。
数据一旦被序列化,就会从脏集合中移除(C1=C1-P)。带宽是稀缺资源,所以我们不会使用原生的状态数据,而是维护了一个经客户端确认收到的状态数据的历史记录,这样就可以进行“增量编码”来改进带宽使用模型,也就是减少带宽的占用。
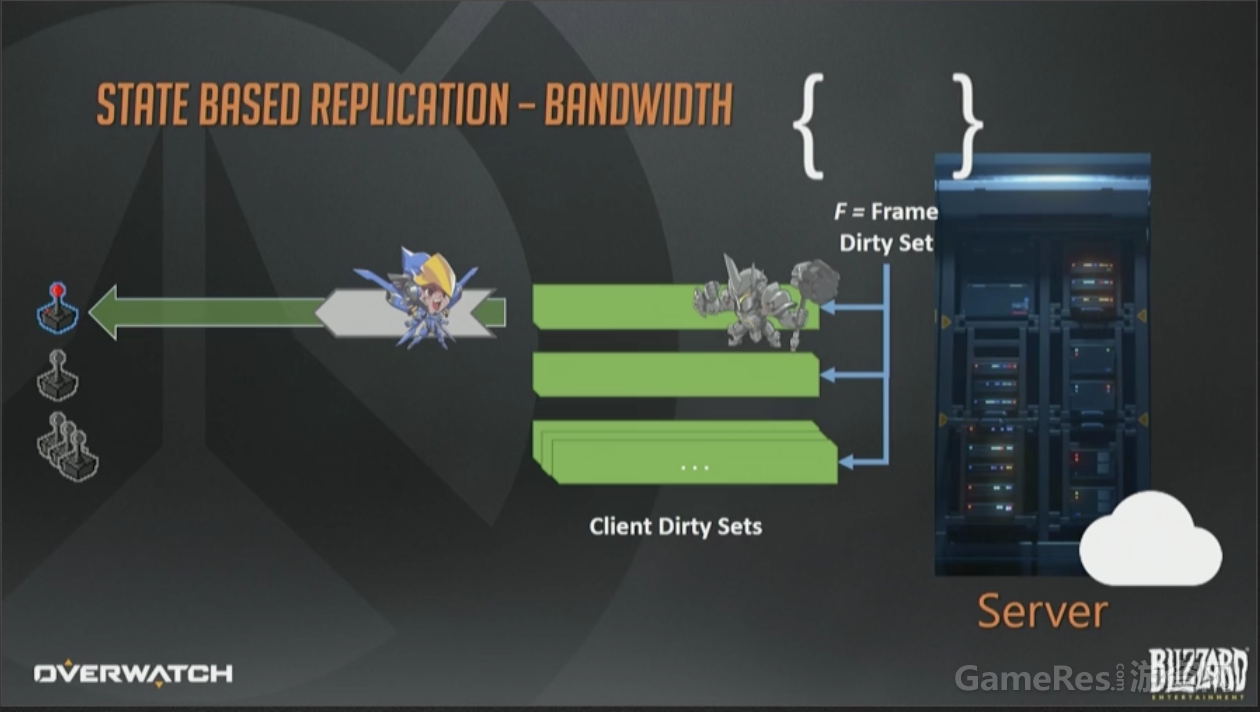
对于大多数帧,我们都有足够的带宽来序列化所有数据。即使不够也没关系,这个例子里,只更新了法拉的状态,因为客户端带宽不足,无法容纳大锤的数据了。无论如何,接收者脏集合都会把它保存下来,最终会在将来的某个时刻成功序列化到某个下行包里。
这就是状态同步模型的一大优点,可以基于带宽质量来调整下行数据大小。
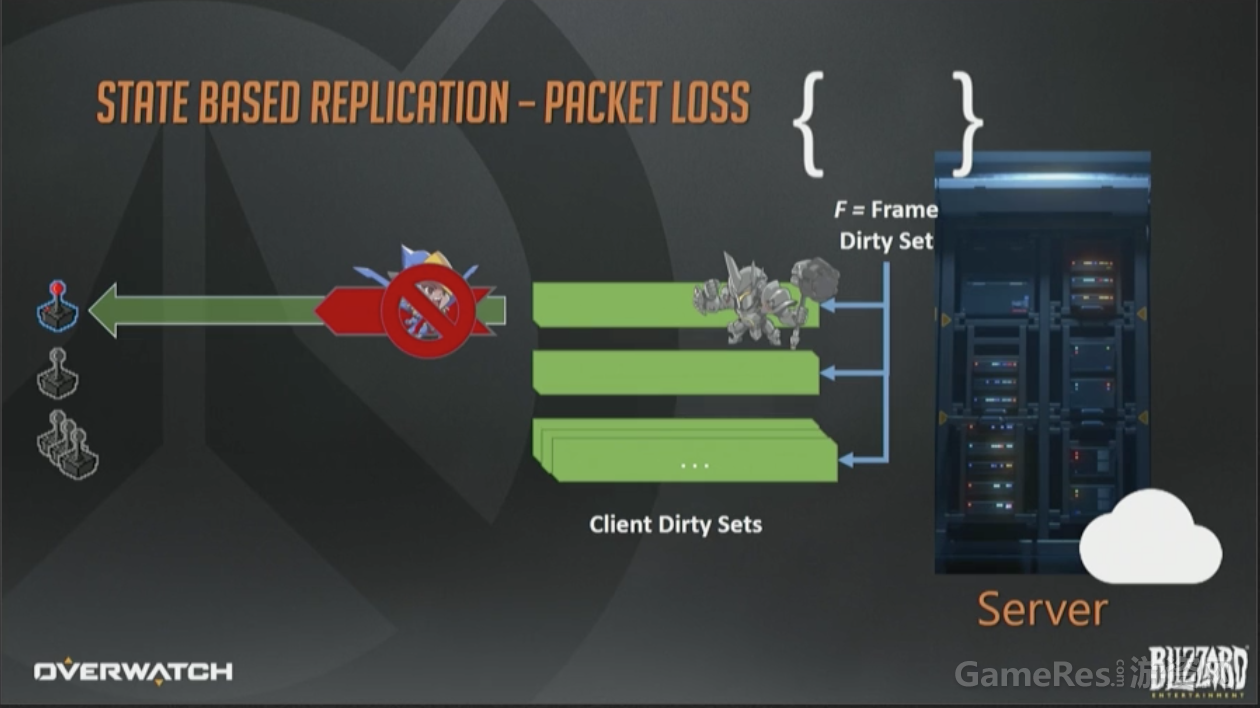
网络协议我们用的是定制的UDP。众所周知,UDP是不可靠协议,意思是说一个数据包可能会成功达到目的地,也可能到达2次,或者乱序到达。这都没关系,我们自己设计的协议可以感知丢包并在必要时重传脏数据。
丢包发生时,只需要简单的把这个数据包合并回脏状态集合,留待将来重传即可。在未来的包里,我们可以把法拉移动这件事,连同该帧其他事件一起重传,例如大锤开盾。
注意, 如果在首次移动包发送完与收到丢包通知之间,法拉再次移动了,那么无需重传旧状态,我们会把新的移动状态序列化到旧状态数据里。
现在聊一下新加入游戏的玩家,是如何追赶上最新的世界状态的。
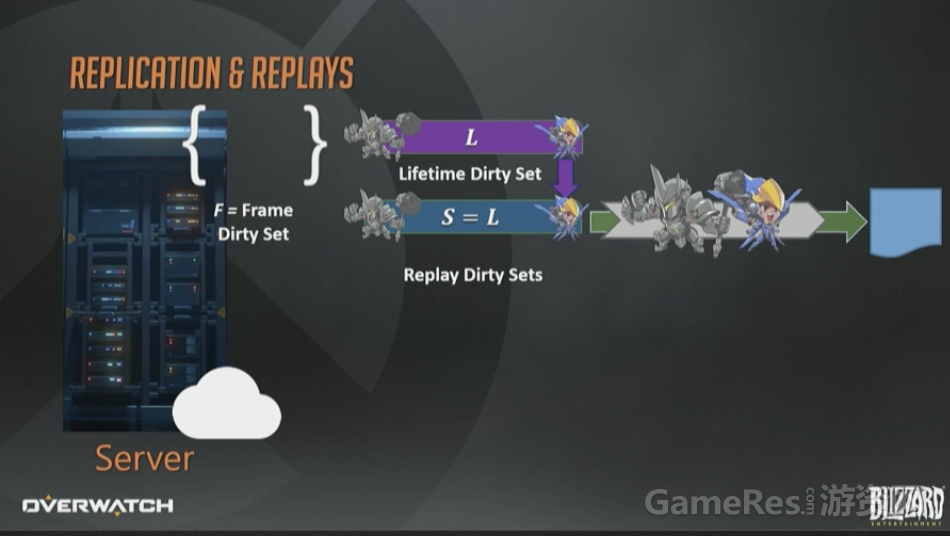
我们在服务器上维护了一个“永久”(lifetime)脏状态集合L,是个全量的脏状态集合s。也就是服务器上所有曾经变脏的状态的“全集”。接下来的事情,你肯定能猜到。
你猜对了,新玩家连上后,我们会把它的初始脏状态集合设置为“永久”脏集合L,这里的设置就是字面意义上的赋值。正常的打包流程最终会把所有变化都下发给这个客户端直到它赶上最新的进度。
一切都很顺利,但是差点忘了, 我们是要做“回放”而我却一直在讲网络序列化。可以把回放数据流近似的认为就是正常游戏的网络数据流,仅仅是接收者有点区别而已,回放系统的接收者叫做“回放快照接收者“(replay snapshot receiver)。
所以实现回放系统的一个方式(并非最好,后面马上优化)就是,在每一帧都保存一个完整世界的瞬时状态快照。
UDP包大小 是有MTU限制的,然而回放流却没有这个限制,每一帧可达几百上千K字节,直到内存耗尽。
但是我们如何保证每次都能得到恰好合适的全量快照呢?
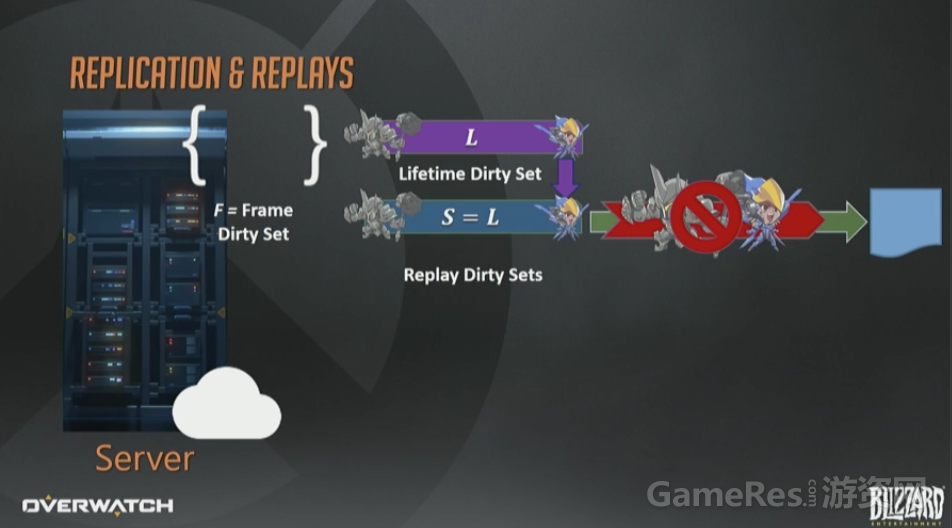
很容易,假装发给回放快照接收者的每个包都丢了就行,然后把永久脏集合重新复制发给回放接收者。这样就可以保证每个快照上每一帧上的每个实体都是脏的。但是就像我上面提示过的,这样做太浪费了。
曾经提到过网络系统是有增量编码的,所以可以基于先前已确认的状态来优化网络流量。
我们又弄了第二个回放接收者,Delta接收者D。这个接收者从不丢弃假想包,每次更新都只包含上一帧到现在的变化。所以基本上直接复制帧脏集然后序列化即可。
现在合起来看一下。
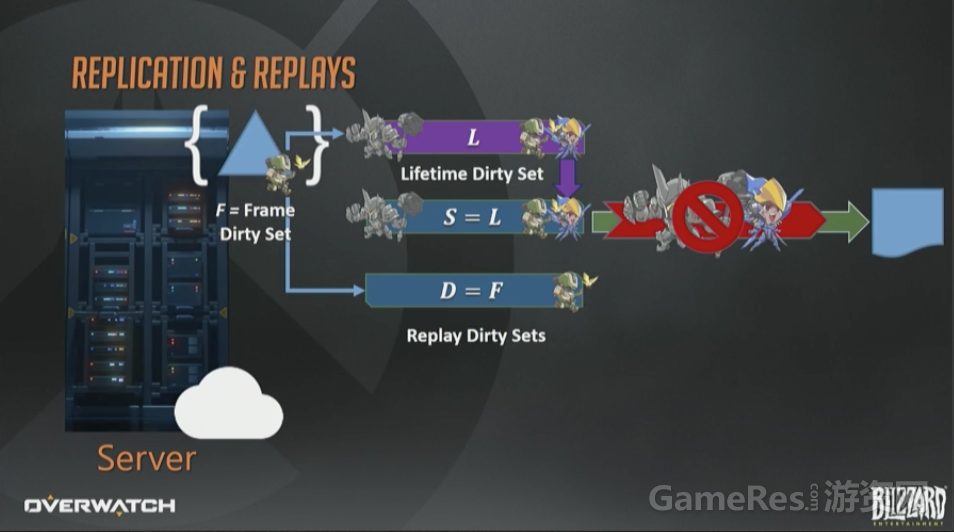
帧的结尾,我们会把新的永久脏状态集合赋值给回放快照目标。同样也会把每帧脏集合序列化给回放Delta目标。然后马上就会有个问题出现:这些数据最终都去哪了?
客户端正常接收者是通过网络包进行的,而回放数据需要通过别的途径。我们维护了两个连续的缓冲区,一个是给快照,一个给Delta。每一帧都会记录这两个缓冲区的偏移和尺寸。
这些连续的缓冲区在整局游戏运行期间都会存在,因为策划可能需要游戏开始到现在的一卷全场最佳镜头(reel,一段连续的影像,无法直译,下文只好统称为“卷”)。
实际看来,每个缓冲区每分钟需要1M的内存,而每帧记录快照所需的内存量比一分钟1M要多得多。所以我们把快照频率降低为每秒1个。
你们中可能有些人想知道Delta的更新频率。服务器的频率是以62.5赫兹(16ms每帧)更新客户端的,死亡重播和回放系统如果都运行在这个频率会使内存和带宽消耗达到3倍之多,所以我们把Delta的频率降低到20Hz。
现在我们终于可以生成回放“卷”(replay reel ,译注:reel这里强调是“卷”)了,这是客户端所需的核心驱动数据。策划同学想要生成阵亡镜头或者全场最佳的时候,他们请求一个“卷”即可。这些”卷”由一个快照加上一系列递增的Delta组成。
要生成”卷”,就要找到”卷”所需开始时间之前的最近的那个快照,然后不停添加Delta直到”卷”的截止时间。这里输出缓冲区的生成也很高效,就是2次内存拷贝而已。
缓冲区会被压缩,添加一些元数据,然后发给客户端。阵亡镜头,亮眼表现和全场最佳都是用的这套机制,而且都是通过这一个System支撑的。
如果这时候你开始怀疑这到底还是不是快照同步了,你绝对是正确的。这是有意而为的。两个World都运转良好:基于状态的模型的十分灵活,可以基于客户端网络质量动态调整;快照同步用于回放”卷”时也带来了简洁性。
现在”卷”已经生产,需要发送给客户端了。为了方便传输,”卷”会被切分为MTU大小的多个片段,然后通过我们开发的BlockTransferSystem在网络上传输。BlockTransferSystem会考虑到网络状况,只有在带宽充足的情况下才会发送。
当然,玩家死亡期间除了盯着凶手,发怒以外什么也做不了,这一点也让我们松了口气。因为他们太全神贯注了,根本不会注意到因为传输大块数据而引起的微小抖动。
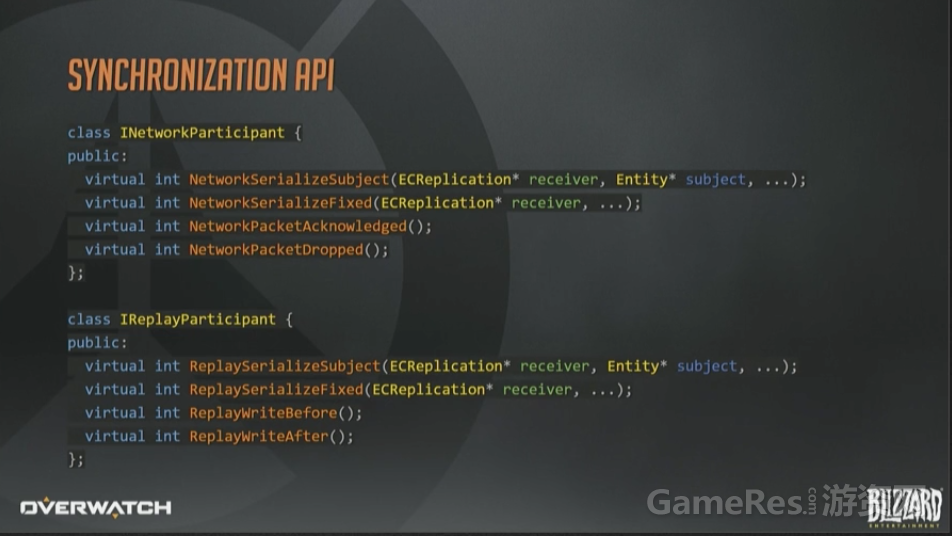
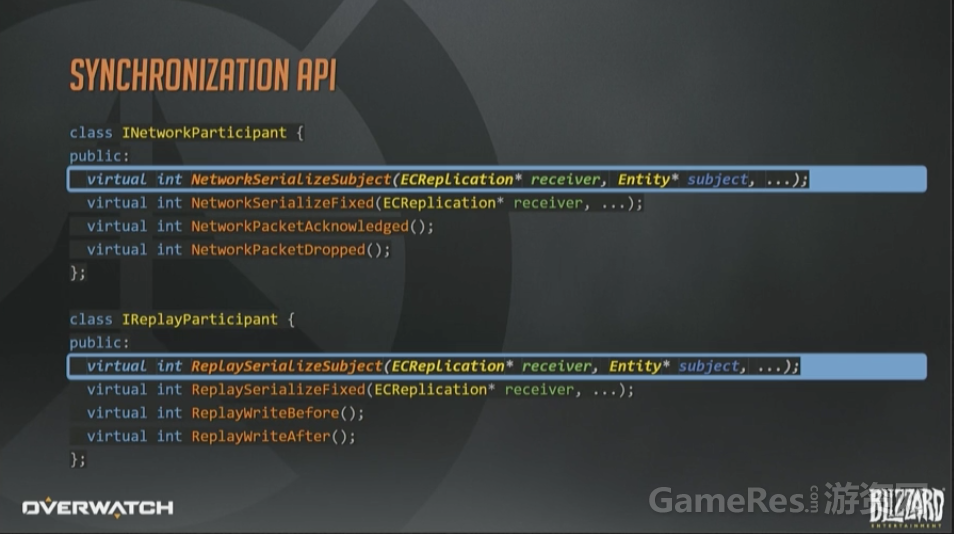
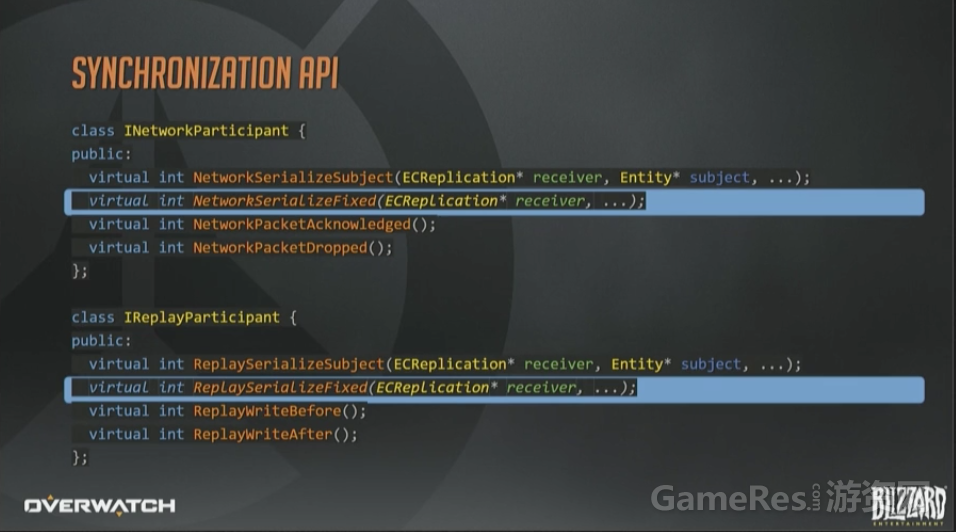
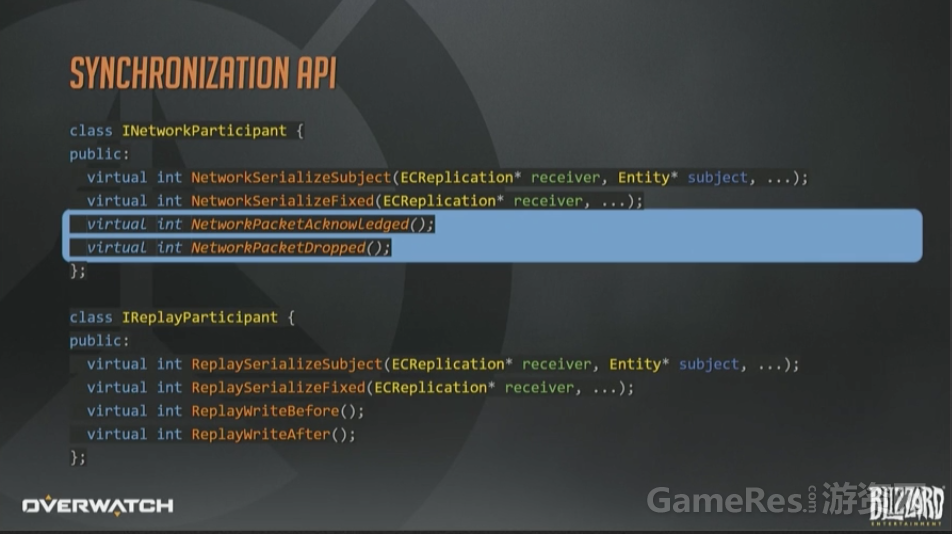
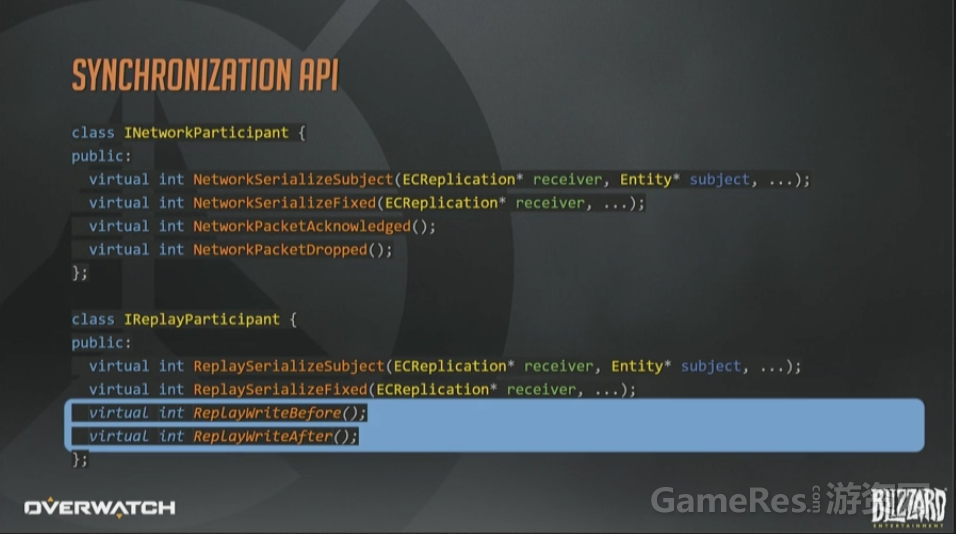
最后看一下同步的API长什么样。这里省略了一些参数;另外返回值应该是枚举而不是整形值,但是用来说明问题已经足够了。
System通常会通过一个内部的通用序列化函数来实现网络参与者和回放参与者两个接口,这两个API的差异很小。例如:网络参与者API会限制带宽,上面已经讲过很多次了。而回放参与者API则完全不用担心这一点。所以很多情况下,回放接口会自行调用含有带宽限制的内部函数,来设置一些永远都达不到的阈值。
网络和回放接口共享序列化策略带来的结果就是,网络复制所节省下的每个字节,在回放系统里也是如此。
这两个接口是每个接收者,针对每个相关Subject(译注:之前有提到,网络相关实体,就是Subject)分别调用一次的。基本就是每个接收者都遍历一次完整的脏集合了。
如果所有的参与者都认为他们对于某个Subject没有需要序列化的数据了,那就可以安全的把这个实体从接收者脏集合中删除了。
这些带Fixed的函数,给参与者提供了一个机会,去同步那些与实体无关的信息,在网络侧,就包括带外控制消息和握手之类的操作。
由于采用了不可靠协议,每个参与网络同步的System,对于每个数据包都需要接受一个ACK或者NACK消息,来判断是否收到或者丢失。
我们就是靠之前已经确认收到过的状态,结合内部帧压缩来增量的发送更新。
另一方面,回放参与者完全不需要收包确认和丢包通知,因为它们从不“丢”包。取而代之的是在序列化过程开始前和结束后使用一对回调函数。如果要举例说明,如何在完成回放帧的序列化之后立即使用这些函数,那就是,对所有来自Delta接收者的内部序列化状态立即ACK,对所有快照接收者上的数据立即NACK。
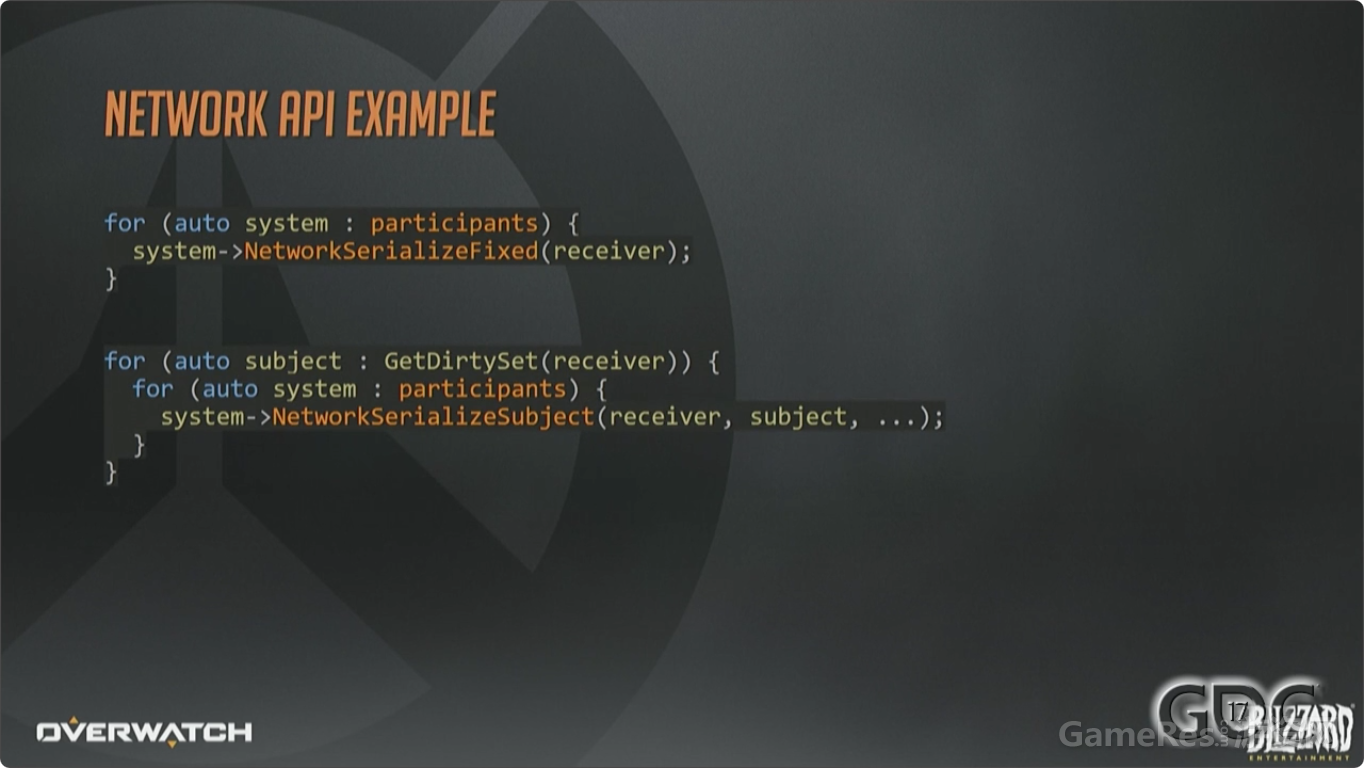
上图是发送数据给网络接收者的API使用的简化版用例。对于该接收者的每个参与者,都执行 Fixed调用,然后获取到该接收者的脏Subject集合,并允许每个System都参与到Subject的序列化过程。
这个例子忽略了很多技术细节,而这些细节几乎可以拿出来单独开设分享议题了,包括:脏状态追踪,相关性,优先级,过滤,带宽模型,丢包与确认,以及其他能单独分享的技术。
回放Before和After的API调用例子。
现在回头看一下参与者API,大家可能会有疑问,为什么这些System的设计没有基于组件,而是基于实体 ,而一个良好的ECS架构实现应该是基于组件的。起初我们的同步API确实是基于组件的,例如MovementSystem简单遍历所有Mover组件然后序列化即可。不幸的是,这种范式有些潜在的关联,假如带宽受限会发生什么呢?通过组件序列化意味着一个System就有可能扼杀其他System序列化能力。除此之外还增加了同一实体被多个包更新的可能性。所以我们团队的实用主义者在这个案例中,从纯粹的ECS转向了非纯ECS,而且是完全可以接受的,也是为了更好地玩家体验。
好了,上面讲过的都是干货,现在来点好玩的:挑战和躺坑。如果说之前讲的是“如何做”,那么现在讲的就是“何时”与“何地”,而“为什么”,最开始我就说过了。
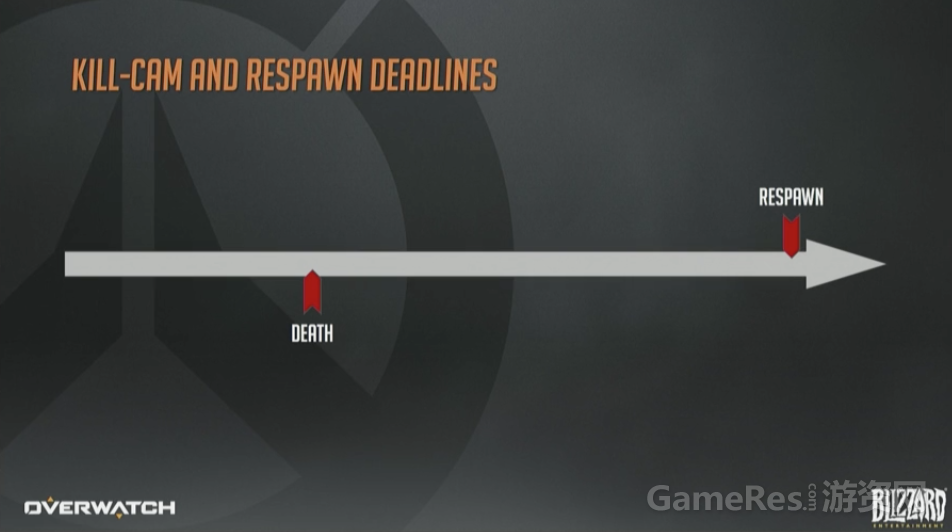
首先,何时下发阵亡镜头的”卷”?阵亡镜头有几个固定时间点:死亡、重生。
这两个点之间的距离是由重生定时器控制的,不同的地图、游戏模式、是否加时及所有策划可以配置的情况下,这个定时器的值都不同。
为了使得阵亡镜头看起来更合理,下发数据时需要比死亡那一刻再超前一点点,这样看起来就没那么突兀了,避免出现一脸懵bi的情况下突然被人爆头。






 App Store
App Store  Steam
Steam 














































 闽公网安备 35020302034348号
闽公网安备 35020302034348号