





Unity性能优化的最佳实践
本文Unity技术经理Ian Dundore将分享改进性能和优化的技巧,这些技巧反映了Unity支持面向数据设计的架构的演变。
Unity不断发展与演变,因此旧技巧可能不再是提升引擎性能的最佳方法。本文我们将介绍从Unity 5.x到Unity 2018.x的一些功能变化,以及如何利用它们。
本文中的最佳实践来自Unite 2018中Ian Dundore的演讲《Unity性能优化的最佳实践》。
优化过程中最困难的任务之一是在发现热点后选择如何优化代码。涉及许多不同的因素:操作系统的平台的CPU和GPU、线程处理、内存访问等。我们很难预先知道哪种优化方法会产生最大的增益效果。
通常情况下,最好在小型测试项目进行原型优化,这样可以更快进行迭代。
但将代码分离到测试项目也会带来相应的挑战。仅仅分离部分代码会改变它所运行的环境。线程时间可能会发生变化,托管堆可能变得更小,或有更少的碎片化。因此,在设计测试项目要小心谨慎。
我们首先要考虑代码的输入内容,以及在修改输入时,代码会作出什么反应:
我们必须考虑好要使用测试项目测量的确切内容。请考虑这个简单操作的测试:对比二个字符串。
在C#API对比二个字符串时,它们会执行特定区域设置的转换,以确保不同字符可以匹配不同文化的其它字符,该过程往往速度非常缓慢。
虽然C#中的大多数字符串API是对文化敏感的,但有一个名为String.Equals的API却不是这样的。
如果你从GitHub打开String.CS,查看String.Equals部分,你会看到下图:一个非常简单的函数会执行一系列检查,然后再把控制权交给EqualsHelper函数,该函数是私有函数,没有反射的话无法直接调用。
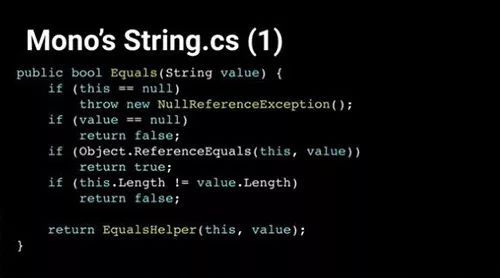
EqualsHelper是一个简单的方法,它会以每次4个字节的速度遍历字符串,对比输入字符串的原始字节。如果它发现不匹配情况,它会停止遍历并返回“False”。
我们也有其它检查字符串相等的方法,看起来最好的方法的是String.Equals的重载,它会接收二个参数:要对比的字符串和StringComparison枚举。
我们已经知道,String.Equals的单参数重载在把控制权交给EqualsHelper前,仅会做少量工作,那么双参数的重载会有什么作用呢?
如果观察双参数重载的代码,它会在进入大型Switch语句前执行一些额外检查。该语句会测试输入的StringComparison枚举的数值。由于我们正在寻找和单参数重载的同等情况,我们要进行序数比较,即逐字节进行比较。
在我们的示例中,控制会经过4次检查,然后再到达StringComparison.Ordinal,此时代码看起来类似单参数的String.Equals重载。这意味着,如果使用String.Equals的双参数重载,而不是单参数重载,处理器会执行一些额外的比较操作。也许这样会使速度变慢,但这是值得测试的。
如果对所有比较字符串相等情况的方法感兴趣的话,你可能不只想测试String.Equals。String.Compare重载可以执行序号比较,此外还有一个方法叫String.CompareOrdinal,它自身拥有二个不同重载。
这是一段手工编码示例可用作参考实现,它是一个简单的函数,其中的长度检查会迭代二个输入字符串中的每个字符,并进行检查。
在查看这些代码后,我们发现有四个不同的测试用例很有效:
运行完几次测试后,无论平台、脚本运行时版本、使用Mono还是IL2CPP,很明显String.Equals是最好的。
请注意:String.Equals是字符串相等运算符==使用的方法,所以别把代码中所有“a==b”的部分改为“a.Equals(b)”。
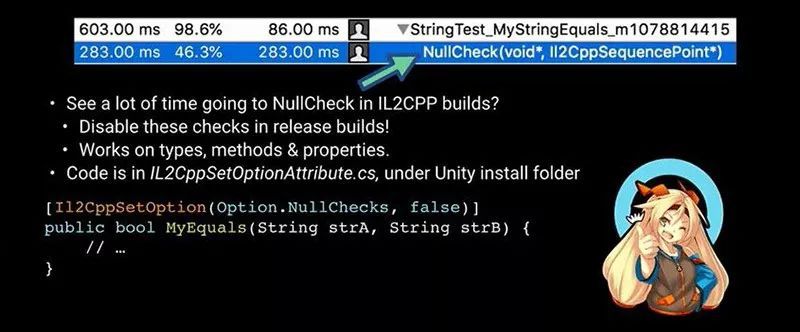
实际上,我们通过观察结果会发现,手工编码的参考实现非常糟糕。查看IL2CPP代码时,我们可以发现在代码进行交叉编译时,Unity会注入一些数组边界检查和Null检查。
这些检查都可以禁用。在Unity安装文件夹中,找到IL2CPP文件夹。在其中,可以找到IL2CPPSetOptionAttributes.cs脚本。把该脚本拖到项目中,然后就可以访问Il2CppSetOptionAttribute。
我们可以使用该属性修饰类型和方法,配置该属性,使它禁用自动Null检查和自动数组边界检查。这样可以加速代码的执行,有时可以大幅加快速度。在这个测试用例中,它会给手工编写的字符串比较方法带来20%的速度提升效果。
Transform
仅仅观察Unity编辑器的层级窗口无法了解Transform组件,但Transform组件在Unity 5和Unity 2018之间发生了很多变化,这也为性能提升过程提供了新的可能性。
回到Unity 4和Unity 5,在创建Transform数据时,对象会被分配到Unity本地内存堆的某个位置。该对象可能在本地内存堆的任何位置,我们无法保证二个连续分配的Transform数据会分配到相邻位置,也无法保证子Transform会分配到父Transform的附近位置。
这意味着,在线性迭代Transform层级时,我们不会在连续内存区域上进行线性迭代。这会造成处理器重复发生停顿,因为它要等待从L2缓存或主内存获取Transform数据。
在Unity后端中,每当Transform的位置,角度或缩放发生改变时,该Transform都会发送OnTransformChanged信息。所有子Transform必须接收此消息,从而使它们可以更新自己的数据,而且它们也可以通知其它和Transform变化有关的组件,例如:在子Transform或父Transform发生变化时,带有碰撞体的子Transform必须更新物理系统。
这个无法避免的信息会造成很多性能问题,而且我们没有内置方法来避免虚假信息。如果你要修改Transform,也会改变它的子对象,无法避免Unity在每次修改后发送OnTransformChanged信息,这样会浪费大量CPU时间。
因为这一细节,对于旧版本Unity最常见的建议之一便是对Transform的改动进行批处理。也就是说,在一帧开始的时候,一次获取Transform的位置和角度信息,在一帧的时间内使用和更新那些缓存的数值,仅在帧的结尾对位置和角度应用一次改动。这是一个很好的建议,一直适用到Unity 2017.2。
在Unity 2017.4和Unity 2018.1中,新的TransformChangeDispatch替代了OnTransformChanged。
TransformChangeDispatch最初在Unity 5.4加入。在该版本中,Transform不再是可以位于Unity本地内存堆中任何位置的独立对象。场景中的每个根Transform都会由连续数据缓冲区表示。该缓冲区叫TransformHierarchy结构,它包含位于根Transform下所有Transform的数据。
此外,TransformHierarchy还存储其中每个Transform的元数据,元数据包含表示特定Transform是否被污染的位掩码,它表示:自从上次Transform被标记为“Clean”(干净)后,它的位置,角度或缩放是否发生变化。它还包含一个特别的位掩码,用于跟踪Unity有哪些系统和特定Transform的改动有关。
通过使用该数据,Unity可以为每个内部系统创建受污染Transform的列表,例如:粒子系统可以查询TransformChangeDispatch,以获取自从上次粒子系统运行FixedUpdate后,数据发生变化的Transform列表。
为了收集改动Transform的列表,TransformChangeDispatch不应该迭代场景中的所有Transform,如果场景包含大量Transform,那会使速度变得非常慢,而且在多数情况下,仅有少量Transform会发生改变。
为了解决该问题,TransformChangeDispatch会跟踪受污染TransformHierarchy结构的列表。当Transform发生变化时,它会把自身和子对象标记为“Dirty”(受污染的),然后使用TransformChangeDispatch系统注册存储它的TransformHierarchy结构。
在Unity中的其它系统请求发生变化的Transform列表时,TransformChangeDispatch会迭代保存在每个受污染TransformHierarchy结构中的每个Transform。带有污染位组和相关位组的Transform会添加到列表中,该列表会返回到提出请求的系统。
因为这种架构,层级分离得越多,可以更好地让Unity功能以粒度等级跟踪变化。存在场景根位置的Transform越多,在变化时要检查的Transform就越少。
但还有潜在影响。在检查TransformHierarchy结构时,TransformChangeDispatch会使用Unity内部的多线程处理系统来划分它需要做的工作。每次某个系统需要从TransformChangeDispatch请求变化的列表时,这种划分操作和组合结果的操作会增加少量性能开销。
Unity的大多数内部系统会在运行前,在每帧请求一次更新内容,例如:动画系统会在它评估场景中所有活动Animators前,请求更新内容。类似的,渲染系统会在开始剔除可见对象列表前,请求对场景中所有活动渲染器的更新。
只有一个系统与众不同,那就是Physics物理系统。
在Unity 2017.1及更早版本,物理更新是同步的。当移动或旋转带有碰撞体的Transform时,会立即更新物理场景。这样会确保碰撞体的改动位置或角度可以反映到物理世界中,从而使光线投射和其它物理查询是准确的。
在Unity 2017.2中,我们把物理功能转变为使用TransformChangeDispatch会造成一些性能问题。在执行光线投射的时候,我们必须查询TransformChangeDispatch,获取发生变化的Transform列表,然后把它们应用到物理世界。这会耗费较多性能,具体取决于Transform Hierarchies的大小,以及代码调用Physics API的方法。
这种行为由新的设置Physics.autoSyncTransforms管理。从Unity 2017.2到Unity 2018.2,这项设置默认设为”True”,每次调用Raycast或Spherecast等物理查询API时,Unity会自动同步物理世界到Transform更新。
这项设置也可以进行修改,既可以在Unity编辑器的Physics Settings修改,也可以通过设置Physics.autoSyncTransforms属性在运行时修改。如果将它设为"False",并禁用自动物理同步功能,那么物理系统仅会查询TransformChangeDispatch,以了解特定时间即在运行FixedUpdate之前的变化。
如果在调用物理查询API时遇到性能问题,我们有二个方法进行处理。
第一种方法,我们可以把Physics.autoSyncTransforms设为“False”,它会消除由TransformChangeDispatch和来自物理查询的物理场景更新造成的峰值情况。但是,如果执行此操作,在执行下一次FixedUpdate之前,对碰撞体的改动不会立即同步到物理场景。
这意味着,如果禁用AutoSyncTransforms,移动碰撞体,然后调用光线投射,使光线的方向为碰撞体新位置的话,光线投射可能不会击中碰撞体。这是因为光线投射会作用于物理场景的上一次更新版本,而那时物理场景还没有使用碰撞体的新位置来更新。
这会造成奇怪的Bug,所以应该小心测试自己的游戏,以确保禁用自动Transform同步功能不会造成问题。如果需要让物理效果通过Transform变化更新物理场景,我们可以调用Physics.SyncTransforms。由于该API速度较慢,因此最好别在每帧多次调用它。
请注意:从Unity 2018.3开始,Physics.autoSyncTransforms将默认设为“False”。
第二种方法,优化TransformChangeDispatch查询时间是重新安排查询和更新物理场景的顺序,使它对新系统更加友好。
由于Physics.autoSyncTransforms设为”True”,所有物理查询都会检查TransformChangeDispatch的变化,但如果TransformChangeDispatch没有任何受污染的TransformHierarchy结构要检查,而且物理系统没有更新的Transform要应用到物理场景,那么物理查询几乎没有任何开销。
所以,我们可以在一次批处理中执行所有物理查询,然后在一次批处理应用所有Transform变化,但是不要把Transform改动和物理查询API的调用混合。
下面的示例展示了它们的区别。

这二个示例之间的性能差异非常明显,在场景仅包含小型Transform层级时,性能差异会更加显着。
音频系统
Unity内部使用一个名为FMOD的系统来播放音频剪辑(AudioClips),FMOD运行在自有线程上,那些线程负责解码和混合音频。
但音频播放不是完全不消耗性能的,一些工作会在主线程上为场景中每个活动音频源(Audio Source)而执行。而在如较老的移动手机这样内核数量较少的平台上,FMOD的音频线程可能会和Unity的主线程及渲染线程竞争处理器内核。
在每一帧上,Unity都会循环所有活动音频源。对于每个音频源,Unity会计算音频源和活动音频监听器之间的距离,以及一些其它参数。该数据用于计算音量衰减,多普勒频移等其它影响音频源的效果。
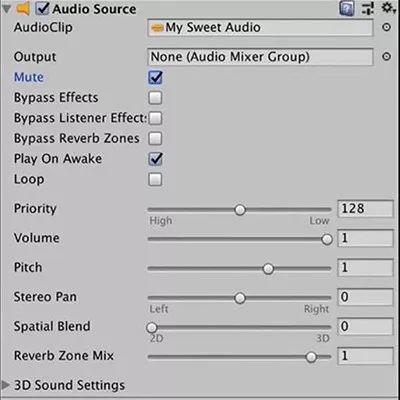
Audio Source组件上的Mute勾选框有一个常见问题:我们可能认为勾选“Mute”会取消所有和静音音频源相关的计算,但实际并非如此。
实际上,在执行包括距离检查在内的所有和音量相关的计算后,Mute设置仅会把Volume参数限制为0。Unity也会把静音的音频源提交给FMOD,而FMOD会无视这些音频源。音频源参数的计算和音频源提交给FMOD的过程都会在Unity性能分析器中作为AudiosSystem.Update显示。
如果你注意到有大量时间分配给该Profiler标记,请检查是否有大量静音的活动音频源。如果是,请考虑禁用静音的Audio Source组件,而不是把它们设为静音,或者禁用它们的游戏对象。你也可以调用AudioSource.Stop,它会停止音频播放。
我们也可以限制Unity的Audio Settings内的声音数量。为此,我们可以调用AudioSettings.GetConfiguration,它会返回包含二个相关数值的结构:一个数值为Virtual Voices虚拟声音数量,另一个是Real Voices真实声音数量。
减少Virtual Voices数量会减小FMOD在检查实际播放的音频源时要检查的音频源数量。减小Real Voice数量会减小FMOD混合的音频源数量,混合的音频源用于产生游戏的音频。
为了修改FMOD使用的Virtual Voices或Real Voice数量,我们可以修改AudioConfiguration结构中的对应数值,该结构由AudioSettings.GetConfiguration返回,然后通过把AudioConfiguration结构作为参数传递给AudioSettings.Reset,重置音频系统为新的配置。
请注意:这样会影响音频播放,所以建议在玩家不会注意到变化的时候进行操作,例如在加载画面或启动的时候。
动画
Unity中有二个不同系统可以用于播放动画:Animator系统和Animation系统。
Animator系统指的是和Animator组件相关的系统,该组件会附加给游戏对象,以给对象添加动画,该系统也和AnimatorController资源有关,该资源会被一个或多个Animator引用。该系统过去曾被称作Mecanim,拥有非常丰富的功能。
在Animator Controller中,我们会定义状态,这些状态可以是Animation Clip或Blend Tree。状态可以组织为图层,在每一帧中,每个图层的活动状态都会进行评估,来自每个图层的结果会混合起来,应用到动画模型上。在二个状态之间过渡时,二个状态都会进行评估。
另一个系统是Animation系统,它由Animation组件表示,使用起来非常简单。每一帧中,每个活动的Animation组件都会线性迭代它附带的动画剪辑的所有曲线,对那些曲线进行评估,然后应用结果。
Animator和Animation这二个系统的区别不仅仅是功能,还有底层实现细节。
Animator系统会大量使用多线程功能,它的性能会在拥有不同内核的CPU上发生很大变化。通常情况下,随着动画剪辑中的曲线数量提高,它会以小于线性的增长速度变化。因此,在评估带有大量曲线的复杂动画时,它的执行效果很好,但Animator系统会有很高的性能开销成本。
虽然Animation系统几乎没有任何开销,它的性能会按照动画剪辑中播放的曲线数量而线性调整。
如果在二个系统播放相同动画剪辑时进行对比,我们会发现明显的区别。
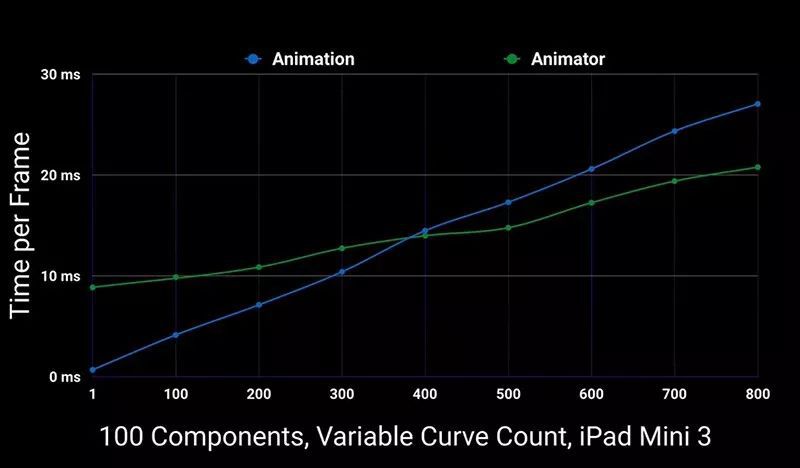
所以在播放动画剪辑时,请选择最适合自己内容复杂度及游戏运行平台的系统。
另一个常见问题是过度使用Animator Controllers中的图层。
在Animator运行时,它会在每帧评估Animator Controllers中的所有图层,这包含Layer Weight设为0的图层,意味着它不会对最终动画结果产生可见影响。
每个额外图层都会在每帧给每个Animator Controller增加额外的计算,所以通常要谨慎使用图层。如果在Animator Controller中有调试、演示或影视的图层,请尝试重新制作它们,把它们合并为现有图层,或在发布游戏前把它们移除掉。
通用绑定和人形绑定
默认情况下,Unity会使用通用绑定(Generic rig)导入动画模型,但在给角色制作动画时,开发人员经常会切换为人形绑定(Humanoid rig),这是有性能开销的。
人形绑定会给Animator系统增加二个额外功能:反向动力学和动画重定向。动画重定向功能很实用,它允许我们对不同角色重用动画。
即使没有使用IK或动画重定向,人形绑定角色的Animator也会在每帧计算IK和重定向数据,这会比使用通用绑定多消耗30%~50%的CPU时间,因为通用绑定不会进行这些计算。如果没有使用人形绑定的特殊功能,你应该使用通用绑定。
Animator的对象池处理
使用对象池是在游戏期间避免发生性能峰值的关键策略,但Animator一直很难用于对象池。在Animator的游戏对象启用时,它必须重新构造中间数据的缓冲区,从而在评估Animator的Animator Controller时使用,这被称为Animator Rebind,它在Unity性能分析器中显示为Animator.Rebind。
在Unity 2018之前,唯一的应对方法是禁用Animator组件,而不是其游戏对象,这会产生副作用:如果角色上有MonoBehaviors,Mesh Colliders或Mesh Renderers,我们可能也想把它们都禁用掉,以便节省角色使用的所有CPU时间,但这样会给代码增加复杂度,而且容易被破坏。
在Unity 2018.1中,我们加入了Animator.KeepControllerStateOnEnable API,该属性默认设为“False”,表示Animator会以它原有的方式使用,即:在禁用Animator时,取消分配它的中间数据缓冲区,在启用Animator时,重新分配这些缓冲区。
如果把该属性设为”True”,Animator将在被禁用时保留它们的缓冲区,这意味着在Animator重新启用时,不会发生Animator.Rebind,从而使Animator可以使用对象池。
小结
本文中关于脚本性能、Transform、音频、动画四个部分的优化技巧为大家介绍到这里,有不少底层的知识内容,虽稍有枯燥,但一旦我们理解清楚方法,就会在实际的开发中让项目性能得到提升。
来源:unity官方平台
原地址:https://mp.weixin.qq.com/s/v15Q9501Sg6_WWPjwTrXkQ
Unity不断发展与演变,因此旧技巧可能不再是提升引擎性能的最佳方法。本文我们将介绍从Unity 5.x到Unity 2018.x的一些功能变化,以及如何利用它们。
本文中的最佳实践来自Unite 2018中Ian Dundore的演讲《Unity性能优化的最佳实践》。
脚本性能
优化过程中最困难的任务之一是在发现热点后选择如何优化代码。涉及许多不同的因素:操作系统的平台的CPU和GPU、线程处理、内存访问等。我们很难预先知道哪种优化方法会产生最大的增益效果。
通常情况下,最好在小型测试项目进行原型优化,这样可以更快进行迭代。
但将代码分离到测试项目也会带来相应的挑战。仅仅分离部分代码会改变它所运行的环境。线程时间可能会发生变化,托管堆可能变得更小,或有更少的碎片化。因此,在设计测试项目要小心谨慎。
我们首先要考虑代码的输入内容,以及在修改输入时,代码会作出什么反应:
- 它会如何应对位于内存连续位置的高度一致的数据?
- 它会如何处理缓存不一致的数据?
- 你从代码运行的循环中删除了多少代码?是否更改了处理器指令缓存的使用情况?
- 代码运行在什么硬件上?该硬件实现分支预测的效果如何?该硬件执行无序微操作的效果如何?它是否有SIMD支持?
- 如果有重度使用多线程的系统,而且运行在带有多核心的系统而不是核心较少的系统,该系统会如何应对?
- 代码的缩放参数是什么?它是否在输入集增长时线性增长,或以大于线性的幅度增长。
我们必须考虑好要使用测试项目测量的确切内容。请考虑这个简单操作的测试:对比二个字符串。
在C#API对比二个字符串时,它们会执行特定区域设置的转换,以确保不同字符可以匹配不同文化的其它字符,该过程往往速度非常缓慢。
虽然C#中的大多数字符串API是对文化敏感的,但有一个名为String.Equals的API却不是这样的。
如果你从GitHub打开String.CS,查看String.Equals部分,你会看到下图:一个非常简单的函数会执行一系列检查,然后再把控制权交给EqualsHelper函数,该函数是私有函数,没有反射的话无法直接调用。
EqualsHelper是一个简单的方法,它会以每次4个字节的速度遍历字符串,对比输入字符串的原始字节。如果它发现不匹配情况,它会停止遍历并返回“False”。
我们也有其它检查字符串相等的方法,看起来最好的方法的是String.Equals的重载,它会接收二个参数:要对比的字符串和StringComparison枚举。
我们已经知道,String.Equals的单参数重载在把控制权交给EqualsHelper前,仅会做少量工作,那么双参数的重载会有什么作用呢?
如果观察双参数重载的代码,它会在进入大型Switch语句前执行一些额外检查。该语句会测试输入的StringComparison枚举的数值。由于我们正在寻找和单参数重载的同等情况,我们要进行序数比较,即逐字节进行比较。
在我们的示例中,控制会经过4次检查,然后再到达StringComparison.Ordinal,此时代码看起来类似单参数的String.Equals重载。这意味着,如果使用String.Equals的双参数重载,而不是单参数重载,处理器会执行一些额外的比较操作。也许这样会使速度变慢,但这是值得测试的。
如果对所有比较字符串相等情况的方法感兴趣的话,你可能不只想测试String.Equals。String.Compare重载可以执行序号比较,此外还有一个方法叫String.CompareOrdinal,它自身拥有二个不同重载。
这是一段手工编码示例可用作参考实现,它是一个简单的函数,其中的长度检查会迭代二个输入字符串中的每个字符,并进行检查。
在查看这些代码后,我们发现有四个不同的测试用例很有效:
- 二个相同字符串,用于测试最差用例的性能。
- 二个字符随机且长度相同的字符串,用于绕过长度检查。
- 二个字符随机且长度相同的字符串,它们的第一个字符相同,用于绕过仅在String.CompareOrdinal中发现的相关优化。
- 二个字符随机而长度不同的字符串,用于测试最佳用例性能。
运行完几次测试后,无论平台、脚本运行时版本、使用Mono还是IL2CPP,很明显String.Equals是最好的。
请注意:String.Equals是字符串相等运算符==使用的方法,所以别把代码中所有“a==b”的部分改为“a.Equals(b)”。
实际上,我们通过观察结果会发现,手工编码的参考实现非常糟糕。查看IL2CPP代码时,我们可以发现在代码进行交叉编译时,Unity会注入一些数组边界检查和Null检查。
这些检查都可以禁用。在Unity安装文件夹中,找到IL2CPP文件夹。在其中,可以找到IL2CPPSetOptionAttributes.cs脚本。把该脚本拖到项目中,然后就可以访问Il2CppSetOptionAttribute。
我们可以使用该属性修饰类型和方法,配置该属性,使它禁用自动Null检查和自动数组边界检查。这样可以加速代码的执行,有时可以大幅加快速度。在这个测试用例中,它会给手工编写的字符串比较方法带来20%的速度提升效果。
Transform
仅仅观察Unity编辑器的层级窗口无法了解Transform组件,但Transform组件在Unity 5和Unity 2018之间发生了很多变化,这也为性能提升过程提供了新的可能性。
回到Unity 4和Unity 5,在创建Transform数据时,对象会被分配到Unity本地内存堆的某个位置。该对象可能在本地内存堆的任何位置,我们无法保证二个连续分配的Transform数据会分配到相邻位置,也无法保证子Transform会分配到父Transform的附近位置。
这意味着,在线性迭代Transform层级时,我们不会在连续内存区域上进行线性迭代。这会造成处理器重复发生停顿,因为它要等待从L2缓存或主内存获取Transform数据。
在Unity后端中,每当Transform的位置,角度或缩放发生改变时,该Transform都会发送OnTransformChanged信息。所有子Transform必须接收此消息,从而使它们可以更新自己的数据,而且它们也可以通知其它和Transform变化有关的组件,例如:在子Transform或父Transform发生变化时,带有碰撞体的子Transform必须更新物理系统。
这个无法避免的信息会造成很多性能问题,而且我们没有内置方法来避免虚假信息。如果你要修改Transform,也会改变它的子对象,无法避免Unity在每次修改后发送OnTransformChanged信息,这样会浪费大量CPU时间。
因为这一细节,对于旧版本Unity最常见的建议之一便是对Transform的改动进行批处理。也就是说,在一帧开始的时候,一次获取Transform的位置和角度信息,在一帧的时间内使用和更新那些缓存的数值,仅在帧的结尾对位置和角度应用一次改动。这是一个很好的建议,一直适用到Unity 2017.2。
在Unity 2017.4和Unity 2018.1中,新的TransformChangeDispatch替代了OnTransformChanged。
TransformChangeDispatch最初在Unity 5.4加入。在该版本中,Transform不再是可以位于Unity本地内存堆中任何位置的独立对象。场景中的每个根Transform都会由连续数据缓冲区表示。该缓冲区叫TransformHierarchy结构,它包含位于根Transform下所有Transform的数据。
此外,TransformHierarchy还存储其中每个Transform的元数据,元数据包含表示特定Transform是否被污染的位掩码,它表示:自从上次Transform被标记为“Clean”(干净)后,它的位置,角度或缩放是否发生变化。它还包含一个特别的位掩码,用于跟踪Unity有哪些系统和特定Transform的改动有关。
通过使用该数据,Unity可以为每个内部系统创建受污染Transform的列表,例如:粒子系统可以查询TransformChangeDispatch,以获取自从上次粒子系统运行FixedUpdate后,数据发生变化的Transform列表。
为了收集改动Transform的列表,TransformChangeDispatch不应该迭代场景中的所有Transform,如果场景包含大量Transform,那会使速度变得非常慢,而且在多数情况下,仅有少量Transform会发生改变。
为了解决该问题,TransformChangeDispatch会跟踪受污染TransformHierarchy结构的列表。当Transform发生变化时,它会把自身和子对象标记为“Dirty”(受污染的),然后使用TransformChangeDispatch系统注册存储它的TransformHierarchy结构。
在Unity中的其它系统请求发生变化的Transform列表时,TransformChangeDispatch会迭代保存在每个受污染TransformHierarchy结构中的每个Transform。带有污染位组和相关位组的Transform会添加到列表中,该列表会返回到提出请求的系统。
因为这种架构,层级分离得越多,可以更好地让Unity功能以粒度等级跟踪变化。存在场景根位置的Transform越多,在变化时要检查的Transform就越少。
但还有潜在影响。在检查TransformHierarchy结构时,TransformChangeDispatch会使用Unity内部的多线程处理系统来划分它需要做的工作。每次某个系统需要从TransformChangeDispatch请求变化的列表时,这种划分操作和组合结果的操作会增加少量性能开销。
Unity的大多数内部系统会在运行前,在每帧请求一次更新内容,例如:动画系统会在它评估场景中所有活动Animators前,请求更新内容。类似的,渲染系统会在开始剔除可见对象列表前,请求对场景中所有活动渲染器的更新。
只有一个系统与众不同,那就是Physics物理系统。
在Unity 2017.1及更早版本,物理更新是同步的。当移动或旋转带有碰撞体的Transform时,会立即更新物理场景。这样会确保碰撞体的改动位置或角度可以反映到物理世界中,从而使光线投射和其它物理查询是准确的。
在Unity 2017.2中,我们把物理功能转变为使用TransformChangeDispatch会造成一些性能问题。在执行光线投射的时候,我们必须查询TransformChangeDispatch,获取发生变化的Transform列表,然后把它们应用到物理世界。这会耗费较多性能,具体取决于Transform Hierarchies的大小,以及代码调用Physics API的方法。
这种行为由新的设置Physics.autoSyncTransforms管理。从Unity 2017.2到Unity 2018.2,这项设置默认设为”True”,每次调用Raycast或Spherecast等物理查询API时,Unity会自动同步物理世界到Transform更新。
这项设置也可以进行修改,既可以在Unity编辑器的Physics Settings修改,也可以通过设置Physics.autoSyncTransforms属性在运行时修改。如果将它设为"False",并禁用自动物理同步功能,那么物理系统仅会查询TransformChangeDispatch,以了解特定时间即在运行FixedUpdate之前的变化。
如果在调用物理查询API时遇到性能问题,我们有二个方法进行处理。
第一种方法,我们可以把Physics.autoSyncTransforms设为“False”,它会消除由TransformChangeDispatch和来自物理查询的物理场景更新造成的峰值情况。但是,如果执行此操作,在执行下一次FixedUpdate之前,对碰撞体的改动不会立即同步到物理场景。
这意味着,如果禁用AutoSyncTransforms,移动碰撞体,然后调用光线投射,使光线的方向为碰撞体新位置的话,光线投射可能不会击中碰撞体。这是因为光线投射会作用于物理场景的上一次更新版本,而那时物理场景还没有使用碰撞体的新位置来更新。
这会造成奇怪的Bug,所以应该小心测试自己的游戏,以确保禁用自动Transform同步功能不会造成问题。如果需要让物理效果通过Transform变化更新物理场景,我们可以调用Physics.SyncTransforms。由于该API速度较慢,因此最好别在每帧多次调用它。
请注意:从Unity 2018.3开始,Physics.autoSyncTransforms将默认设为“False”。
第二种方法,优化TransformChangeDispatch查询时间是重新安排查询和更新物理场景的顺序,使它对新系统更加友好。
由于Physics.autoSyncTransforms设为”True”,所有物理查询都会检查TransformChangeDispatch的变化,但如果TransformChangeDispatch没有任何受污染的TransformHierarchy结构要检查,而且物理系统没有更新的Transform要应用到物理场景,那么物理查询几乎没有任何开销。
所以,我们可以在一次批处理中执行所有物理查询,然后在一次批处理应用所有Transform变化,但是不要把Transform改动和物理查询API的调用混合。
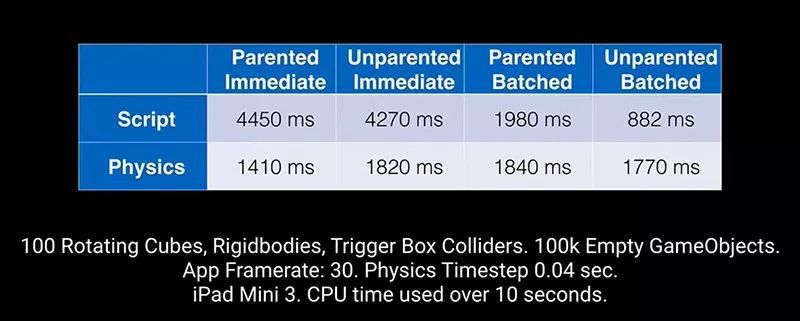
下面的示例展示了它们的区别。
这二个示例之间的性能差异非常明显,在场景仅包含小型Transform层级时,性能差异会更加显着。
音频系统
Unity内部使用一个名为FMOD的系统来播放音频剪辑(AudioClips),FMOD运行在自有线程上,那些线程负责解码和混合音频。
但音频播放不是完全不消耗性能的,一些工作会在主线程上为场景中每个活动音频源(Audio Source)而执行。而在如较老的移动手机这样内核数量较少的平台上,FMOD的音频线程可能会和Unity的主线程及渲染线程竞争处理器内核。
在每一帧上,Unity都会循环所有活动音频源。对于每个音频源,Unity会计算音频源和活动音频监听器之间的距离,以及一些其它参数。该数据用于计算音量衰减,多普勒频移等其它影响音频源的效果。
Audio Source组件上的Mute勾选框有一个常见问题:我们可能认为勾选“Mute”会取消所有和静音音频源相关的计算,但实际并非如此。
实际上,在执行包括距离检查在内的所有和音量相关的计算后,Mute设置仅会把Volume参数限制为0。Unity也会把静音的音频源提交给FMOD,而FMOD会无视这些音频源。音频源参数的计算和音频源提交给FMOD的过程都会在Unity性能分析器中作为AudiosSystem.Update显示。
如果你注意到有大量时间分配给该Profiler标记,请检查是否有大量静音的活动音频源。如果是,请考虑禁用静音的Audio Source组件,而不是把它们设为静音,或者禁用它们的游戏对象。你也可以调用AudioSource.Stop,它会停止音频播放。
我们也可以限制Unity的Audio Settings内的声音数量。为此,我们可以调用AudioSettings.GetConfiguration,它会返回包含二个相关数值的结构:一个数值为Virtual Voices虚拟声音数量,另一个是Real Voices真实声音数量。
减少Virtual Voices数量会减小FMOD在检查实际播放的音频源时要检查的音频源数量。减小Real Voice数量会减小FMOD混合的音频源数量,混合的音频源用于产生游戏的音频。
为了修改FMOD使用的Virtual Voices或Real Voice数量,我们可以修改AudioConfiguration结构中的对应数值,该结构由AudioSettings.GetConfiguration返回,然后通过把AudioConfiguration结构作为参数传递给AudioSettings.Reset,重置音频系统为新的配置。
请注意:这样会影响音频播放,所以建议在玩家不会注意到变化的时候进行操作,例如在加载画面或启动的时候。
动画
Unity中有二个不同系统可以用于播放动画:Animator系统和Animation系统。
Animator系统指的是和Animator组件相关的系统,该组件会附加给游戏对象,以给对象添加动画,该系统也和AnimatorController资源有关,该资源会被一个或多个Animator引用。该系统过去曾被称作Mecanim,拥有非常丰富的功能。
在Animator Controller中,我们会定义状态,这些状态可以是Animation Clip或Blend Tree。状态可以组织为图层,在每一帧中,每个图层的活动状态都会进行评估,来自每个图层的结果会混合起来,应用到动画模型上。在二个状态之间过渡时,二个状态都会进行评估。
另一个系统是Animation系统,它由Animation组件表示,使用起来非常简单。每一帧中,每个活动的Animation组件都会线性迭代它附带的动画剪辑的所有曲线,对那些曲线进行评估,然后应用结果。
Animator和Animation这二个系统的区别不仅仅是功能,还有底层实现细节。
Animator系统会大量使用多线程功能,它的性能会在拥有不同内核的CPU上发生很大变化。通常情况下,随着动画剪辑中的曲线数量提高,它会以小于线性的增长速度变化。因此,在评估带有大量曲线的复杂动画时,它的执行效果很好,但Animator系统会有很高的性能开销成本。
虽然Animation系统几乎没有任何开销,它的性能会按照动画剪辑中播放的曲线数量而线性调整。
如果在二个系统播放相同动画剪辑时进行对比,我们会发现明显的区别。
所以在播放动画剪辑时,请选择最适合自己内容复杂度及游戏运行平台的系统。
另一个常见问题是过度使用Animator Controllers中的图层。
在Animator运行时,它会在每帧评估Animator Controllers中的所有图层,这包含Layer Weight设为0的图层,意味着它不会对最终动画结果产生可见影响。
每个额外图层都会在每帧给每个Animator Controller增加额外的计算,所以通常要谨慎使用图层。如果在Animator Controller中有调试、演示或影视的图层,请尝试重新制作它们,把它们合并为现有图层,或在发布游戏前把它们移除掉。
通用绑定和人形绑定
默认情况下,Unity会使用通用绑定(Generic rig)导入动画模型,但在给角色制作动画时,开发人员经常会切换为人形绑定(Humanoid rig),这是有性能开销的。
人形绑定会给Animator系统增加二个额外功能:反向动力学和动画重定向。动画重定向功能很实用,它允许我们对不同角色重用动画。
即使没有使用IK或动画重定向,人形绑定角色的Animator也会在每帧计算IK和重定向数据,这会比使用通用绑定多消耗30%~50%的CPU时间,因为通用绑定不会进行这些计算。如果没有使用人形绑定的特殊功能,你应该使用通用绑定。
Animator的对象池处理
使用对象池是在游戏期间避免发生性能峰值的关键策略,但Animator一直很难用于对象池。在Animator的游戏对象启用时,它必须重新构造中间数据的缓冲区,从而在评估Animator的Animator Controller时使用,这被称为Animator Rebind,它在Unity性能分析器中显示为Animator.Rebind。
在Unity 2018之前,唯一的应对方法是禁用Animator组件,而不是其游戏对象,这会产生副作用:如果角色上有MonoBehaviors,Mesh Colliders或Mesh Renderers,我们可能也想把它们都禁用掉,以便节省角色使用的所有CPU时间,但这样会给代码增加复杂度,而且容易被破坏。
在Unity 2018.1中,我们加入了Animator.KeepControllerStateOnEnable API,该属性默认设为“False”,表示Animator会以它原有的方式使用,即:在禁用Animator时,取消分配它的中间数据缓冲区,在启用Animator时,重新分配这些缓冲区。
如果把该属性设为”True”,Animator将在被禁用时保留它们的缓冲区,这意味着在Animator重新启用时,不会发生Animator.Rebind,从而使Animator可以使用对象池。
小结
本文中关于脚本性能、Transform、音频、动画四个部分的优化技巧为大家介绍到这里,有不少底层的知识内容,虽稍有枯燥,但一旦我们理解清楚方法,就会在实际的开发中让项目性能得到提升。
来源:unity官方平台
原地址:https://mp.weixin.qq.com/s/v15Q9501Sg6_WWPjwTrXkQ
评论
登录 后参与讨论
暂无评论,来抢沙发









 闽公网安备 35020302034348号
闽公网安备 35020302034348号