本文来自特约撰稿人 Abhimanyu 和 Victoria。文中所述的测试是他们在 Flaregames 工作期间完成的。
新款游戏马上就要发布了?应用平台有没有承诺在商城中给你提供曝光度?想要预测平台提供的曝光度能带来多少安装量?如果你想要精准的数字,那得去问问魔力水晶球。如果你想做个大概的估算,请继续看下文!
许多游戏开发者都明显意识到,通过平台主推获得的安装量已不复当年之多(iOS 平台更是如此)。但在商城的显要位置曝光依然能带来可观的流量,这些位置是游戏公司的必争之地。令人遗憾的是,预测主推周/主推月的安装量让很多团队都感到扎心。不足为奇的是,在对项目营收进行合理预估时,预测安装量也是项目经理和高管们最重要和最头疼的工作。每家公司都会通过不同的方法来解决这个问题,大多数公司会根据同类游戏的安装量进行预测。但这类方法的准确率往往很低,而且解读会收到个人观点的影响。
我们认识到这个问题的困难性且没有关于这一话题的公开分析,于是打算采用一些科学的方法来解决这个看似很抽象的预测问题。经过认真分析影响潜在客户安装决定的关键因素后,我们决定测试以下这种假设:游戏首发周的安装量与游戏的主推版位、类型和艺术风格之间存在关系。下面的分析证实了这种假设是正确的。我们希望通过本文为游戏公司介绍一种能够付诸实践的方法,并提供一些相关的研究发现来助力行业获得进一步发展。
分析方法
与任何同类研究一样,这套分析方法包含了建立数据集、开展统计测试和创建模型 3 个阶段。
具体如下:
- 分析了在 2018 年 4 月 2 日至 9 月 27 日间主推的 150 多款游戏
- 每款游戏都按主推版位、类型和艺术风格进行分类
- 采用 Kruskal-Wallis (KW) (1)假设测试来检验假设
- 我们建立了一个线性回归模型,将假设游戏的 3 种变量分类作为输入,并输出游戏在首发周/首发月的预测安装量范围
在建立基础数据集时,我们使用了 App Annie 提供的优质服务来收集相关游戏的 iOS 自然安装量估值和主推日期。我们假设游戏的全球 iOS 主推日期与 iOS 美国主推日期一致。因此,这次分析仅限于 iOS 数据。
拥有大型 IP 的付费游戏和精选游戏未纳入基础数据集考量。大型 IP 游戏包括(但不限于)基于大型电影、电视剧和名人开发的游戏,以及原创爆款游戏的续作。值得一提的是,我们在第一轮分析中确实试图纳入大型 IP 游戏,但逐渐意识到这是一个非常棘手的难题。我们最终得出的结论是,影响大型 IP 游戏首发周/首发月安装量的因素数量超出了本次分析的范畴。但我们机会以后建立一个模型来解决这个问题。
变量定义
数据集中的每款游戏按 3 种变量进行分类,即主推版位、类型和艺术风格。与这些变量相关的赋值例如:
我们采用了 Game Refinery 和 Michail Katkoff (2)制定的游戏分类法来划分游戏类型(见下图)。例如,“休闲游戏”是一种游戏类别,“街机游戏”是一种游戏类型,“平台游戏”是一种子类型。由于基础数据集有限且复杂的分类可能无法带来具有实操性的研究结果,因此数据点分类没有考虑使用子类型。虽然如此,但应注意到子类型显然可以在更大的数据集中使用。
验证假设
我们再提一下初始的假设:游戏首发周的安装量与游戏的主推版位、类型和艺术风格之间存在关系。
我们已使用 Kruskal-Wallis (KW) 假设测试证实上述假设是正确的。我们进一步利用这个假设验证了首发周的安装量也存在类似的关系。下表通过 P 值概括反映了各项测试的意义,P 值应小于 0.10 才具有统计学意义。整体而言,每种变量都在各种优势方面显示出了统计学意义。我们的研究结论概括如下:
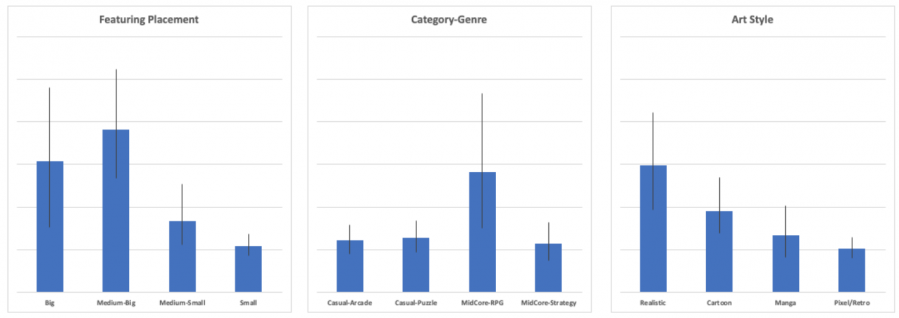
虽然“艺术风格”变量的表现显然是最弱的,但随着数据集规模的增加,它与安装量的关系会变得更强。“类型”变量也是如此。与此同时,我们一定要注意到,显著的结果与优势的相关度很高,无论游戏的优势是什么。
接着,我们开展了以下工作:
- 针对各个变量值建立安装量范围
- 建立模型利用这些不同强度的变量来提供一个关于假设游戏的首发周/首发月安装量的定向预测
下图是首发周安装量范围对应的一些变量值。蓝色柱条代表平均值,黑色细线代表敏感度范围。一个有趣的发现是,“大型”主推为首发周带来的安装量范围并不一定会高于“中大型”主推带来的安装量范围,这进一步证明了用户在决定下载一款游戏时存在更多的变量。
我们现在能谈谈未来了吗?
根据以上分析,下一步显然是建立模型来对假设/未发布的游戏的首发周/首发月安装量范围进行定向预测。需要指出的是,150 多款游戏的基础数据集并不足以创建稳定的预测模型,但我们可以通过一些务实的方法来尝试建立一个预测模型。
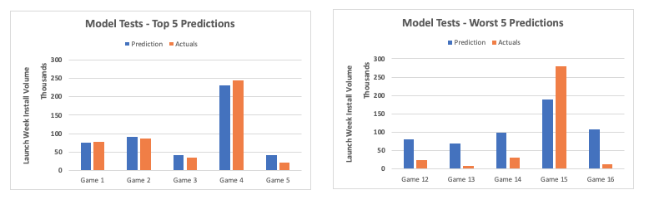
我们主要尝试使用 3 种变量作为输入来创建一个简单的线性回归模型,并使用未纳入基本数据集的主推游戏来进行测试。我们希望测试结果能够证明建立一个复杂的统计模型是合理的,并且我们很高兴看到一些结果能够证明在这方面投入额外的时间是合理的。下图是我们的模型预测的首发周安装量和 App Annie 下载预估提供的实际安装量的对比:
从上图可以看出,我们的预测有时准有时不准,平均误差范围为 +/-5 万。导致这种情况的原因有两个:一是我们的模型设计还比较原始,二是基础数据集规模较小。可以肯定的是,通过尝试不同且可能更复杂的统计模型,同时扩大基本数据集的规模,我们的预测精度还能进一步提高。由于我们很容易在这方面过度投入,因此在模型设计的复杂性和时间投入之间找到平衡是关键,并且应该由这些定向预测要达到的目标来驱动。
有效预测首发周安装量的方法
我们通过上述的测试可以看出,游戏首发周/首发月的安装量与主推版位、类型和艺术风格之间显然存在关系。在此基础上,我们将通过不断增加数据集、尝试更复杂的统计模型以及考虑 IP、平台、主题、应用大小和首发市场等关键变量来探寻这些变量之间更紧密的关系。
我们可以很自信地说,在预测游戏首发周/首发月的安装量时,应该坚持采用定向预测来估算大概范围,而不是绞尽脑汁寻找一个准确的数字。希望上述方法和研究结论可以帮助大家更好地制定业务计划!
注释:
(1)Kruskal-Wallis (KW) 假设测试
https://en.wikipedia.org/wiki/Kruskal%E2%80%93Wallis_one-way_analysis_of_variance
(2)Game Refinery 和 Michail Katkoff 游戏分类法
http://www.gamerefinery.com/new-genre-taxonomy-and-why-we-need-it/
更多Facebook出海指南可访问Facebook专题






 App Store
App Store  Steam
Steam 











 闽公网安备 35020302034348号
闽公网安备 35020302034348号