7月19日,游戏开发者大会(GDC)正式开幕,这是一场全球游戏开发者的盛会。开幕当天,网易伏羲实验室的研究员王蒙博士进行了精彩的分享,他于2018年正式加入网易,目前主要负责模仿学习在游戏中的研究和应用落地工作,在AAAI、IJCAI、COG等AI和游戏相关国际顶会上发表多篇论文。
网易伏羲实验室在人工智能领域积极探索,推出了游戏行业人工智能解决方案,横跨AI反外挂、AI竞技机器人、AI 对战匹配以及 AI 剧情动画制作四大AI能力,实现了AI 技术在游戏行业的新突破。本次分享的内容就是源于AI竞技机器人在游戏中的运用经验
以下是分享实录:
王蒙(怀沙):大家好,我是来自网易伏羲实验室强化学习组的研究员王蒙,很高兴能够有机会参加本次GDC AI峰会,今天我分享的主题是“Beyond Pre-training: Experiences of Applied Imitation Learning in Game AI”,亦即我们将模仿学习应用在游戏场景下的一些经验和体会
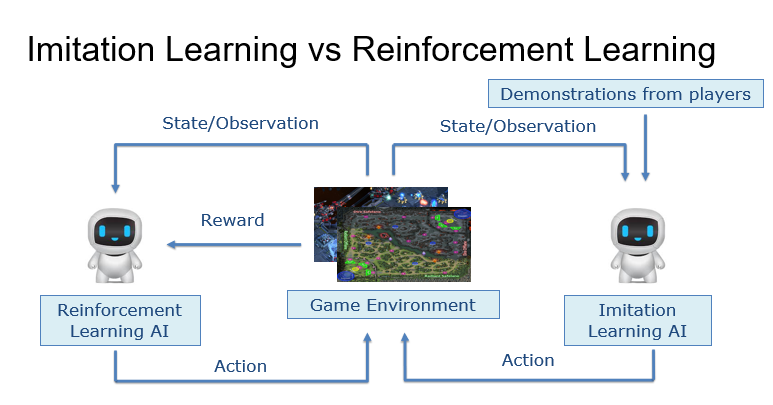
近年来,强化学习在游戏领域获得了快速的发展,在围棋、Atari、Dota、星级争霸等一系列复杂的游戏中都达到了人类顶尖选手的水平。强化学习主要通过智能体与游戏环境不断交互获得大量样本,并根据这些样本来优化自身总奖励回报的方式去优化自身的策略。模仿学习是另一种解决序列决策问题的思路,与强化学习不同,模仿学习一般都是从事先收集的人类数据中去模仿人类解决问题的过程,来优化自身的策略。下图给出了模仿学习和强化学习的一些异同
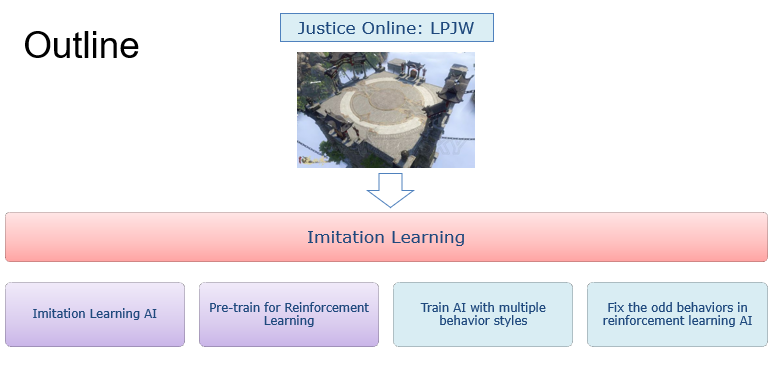
游戏天然就会有大量的人类玩家参与,因此也是一个应用模仿学习的理想场景,在AlphaGo,AlphaStar等顶尖强化学习AI的开发过程中,都有模仿学习的影子。在这些工作中,模仿学习一般会用来预训练一个基础的AI,以便于减小智能体训练过程中的探索空间,即先通过学习人类专家的数据(棋谱,游戏replay数据)等,得到一个具有一定水平的预备AI,然后再在此AI的基础上,引入强化学习训练来继续提升该AI的水平。除了这种常规的模仿学习应用方式以外,我们还进行了更多的探索,尝试将模仿学习和强化学习结合起来去解决一些更复杂的问题,得到了一些有趣的结果。我分享的主要内容可以分为以下四个方面:直接应用模仿学习及其效果、模仿学习预训练对强化学习的加速作用、基于模仿学习进行不同风格AI的训练、模仿学习和强化学习相结合来得到更像人的AI。
为了应用模仿学习,我们收集了逆水寒游戏流派竞武玩法中的玩家操作数据,后续的算法训练场景也主要是在该玩法中进行的。
首先来介绍下我们单独应用模仿学习算法进行AI训练的情况,由于收集到的全部玩家的数据量相对是比较大的,并且玩家的水平也不尽相同,我们首先需要从中筛选出一些高质量的数据。在这一部分,我们的规则相对比较简单,主要可以分为两部分:一部分是保证一场战斗数据的完整性(如:排除非正常结束的战斗),另一部分是保证较高的战斗水平(如:低rank玩家击败高rank玩家)。在得到数据后,我们还需要对数据进行解析,获得可以用于智能体的(state, action)数据对。对于state部分,首先我们会以与敌人的距离和角度以及与地图中心的距离和角度的形式记录玩家的相对位置。对于技能相关信息,我们将记录每个技能的可用情况;最后,对于每个玩家,还有一些与玩家状态相关的属性信息,例如血量、魔法值、buffers 和 debuffers等,我们将所有这些信息都记录在名为 status 的部分中。action可以分为两部分,第一部分包括移动、跳跃和躲避相关的动作。对于移动和跳跃,我们为每一个设置了八个离散的方向,包括向上、向后、向左、向右以及向左、向左、向左、向后、向后,对于躲避,我们只使用上,后,左,右四个主要方向。action的第二部分是技能,我们为每个技能设置一个动作,并为需要目标的技能手动设置目标。我们要解决的下一个问题是每个玩家的数据有限,而不同的玩家可能会有相互矛盾的行为模式,如果我们将所有数据混合在一起训练一个模型,这些相互矛盾的数据很可能会影响训练效果。为了解决这个问题,我们引入了特征增强并添加了一些重要的信息来帮助模型区分来自不同玩家的数据。经过多次实验,我们发现每场战斗花费的时间和每场战斗如何结束是两个重要的因素,因此我们为每个state添加了两个维度,分别代表了战斗时间和战斗结果。此外,由于我们没有使用 LSTM 或 GRU 等序列模型,我们添加了玩家或智能体在上一步执行的动作来捕获序列信息。
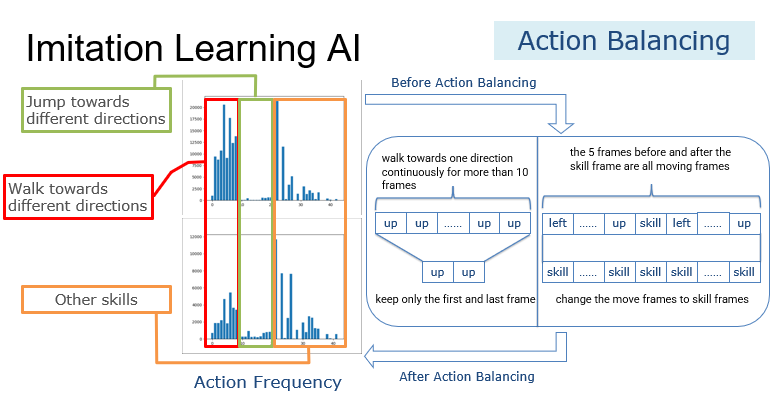
将玩家的日志解析为(state, action)数据对后,我们发现数据中不同动作的频率差异很大。下图中的左上分布图显示了原始数据中每个动作的原始频率。我们可以看到,除了几个技能外,移动动作在这个分布中占主导地位。我们使用以下两个规则对数据进行预处理,以使动作的分布更加平衡。
- 首先,如果玩家连续向一个方向行走超过10帧,我们将只保留第一帧和最后一帧。这将大大减少移动动作的数量。
- 接下来,如果技能帧前后5帧都是移动帧,我们会将这些移动帧都改成技能帧,因为我们假设对于人类玩家来说,如果在这一帧施放技能是合适的,那么前五帧和后五帧也可能适合这个技能,因为人类的反应时间可能已经超过五帧所对应的时间了。经过这些预处理,虽然还有很多移动动作,但是动作的分布更加均衡,如下图的左下分布图所示。
最终,在仅使用模仿学习的情况下,我们得到了一个相当于中级强化学习AI的模型,其对我们的中级强化学习 AI 的胜率约为 47.3%,该中级强化学习AI 在线上超过了90% 的人类玩家。
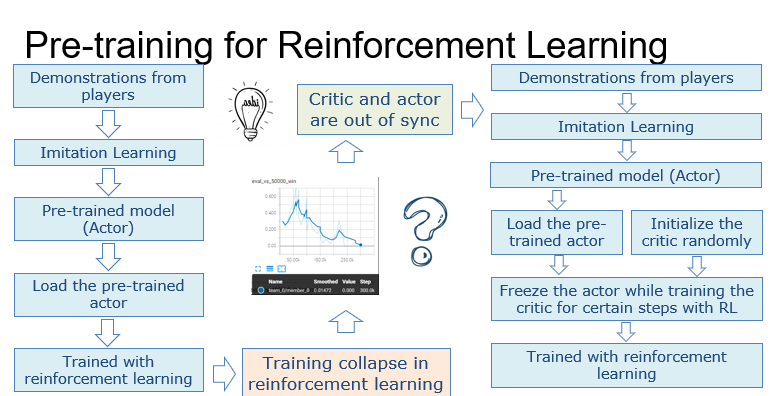
在尝试了纯模仿学习之后,我们想看看模仿学习是否可以加速强化学习的训练过程。由于模仿学习模型类似于强化学习中的actor,所以我们引入了基于Actor-Critic的IMPALA作为我们的强化学习算法。一开始,我们只是将预先训练好的模仿学习模型加载到actor中,然后继续用强化学习算法进行训练。但是训练总是在强化学习阶段的早期就崩溃了。在对代码和模型进行分析之后,发现训练崩溃的主要原因是在模仿学习转向强化学习的初始阶段,actor和critic的能力并不匹配。具体来说,当actor加载我们的模仿学习模型时,已经具有了较强的能力了,但是由于critic网络在模仿学习阶段并没有被训练过,仍然在使用随机权重参数,导致了critic无法正确评估actor决策的优劣,从而导致训练过程崩溃。为了解决这个问题,我们在强化学习训练的初始阶段增加了一个额外的critic训练阶段。在这个阶段中,虽然预训练的模仿学习模型被加载到了actor中,但它的权重会被冻结,只有critic网络的参数会被更新。这个阶段会持续一段时间,直到我们发现critic稳定下来之后,才会切换到actor和critic同步训练的模式。
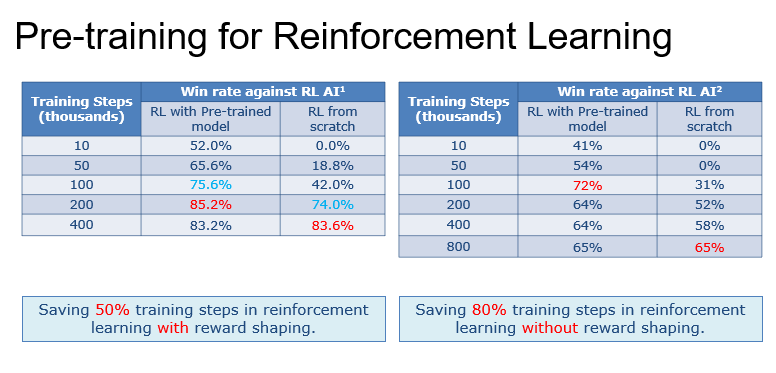
在最终结果上,我们比较了两种不同的情况:
- 首先,我们比较了引入reward shaping的情况下模仿学习的加速效果,结果如下图左表所示,与从头开始训练相比,预训练的模仿学习模型可以节省约50%的迭代次数。
- 其次,我们移除了强化学习中reward shaping,验证在这种更难的情况下模仿学习的加速效果,结果如下图右表所示,与从头开始训练相比,预训练的模仿学习模型可以节省80%的迭代次数。
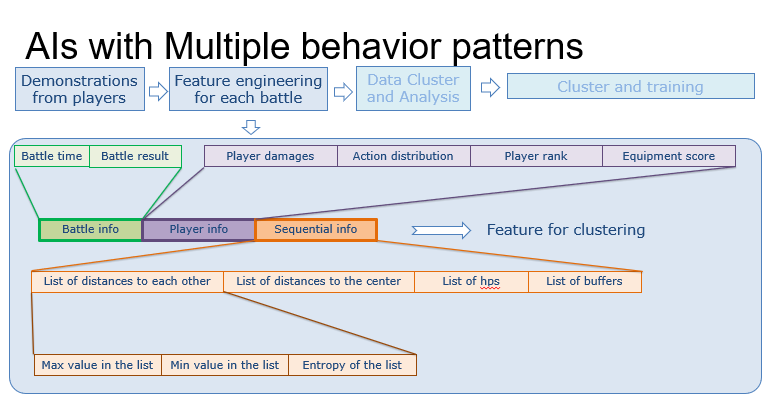
接下来,我们尝试通过模仿学习来训练具有不同行为模式的AI。解决方案的整体流程如下图所示。
在收集了玩家数据后,我们会为每场战斗设计一些特征,然后利用聚类算法以无监督的方式将数据分成几类。最后,我们可以对这些类别中的每一个应用模仿学习,产生一个对应模型,每个模型代表相应类别的战斗风格。在这个过程中,首先要做的是设计聚类所需的特征。我们将特征分为三个部分。
- 第一个是战斗信息,包括战斗时间和战斗结果,如前所述。
- 第二部分是玩家信息,包括玩家造成的伤害、玩家的动作分布以及玩家的等级和装备评分。这些信息描绘了玩家的属性和技能偏好。
- 最后一部分是序列信息,包括两个玩家之间的距离序列、玩家到地图中心的距离序列、玩家血量序列和玩家buffer序列。由于我们要聚类的对象是一场战斗,亦即一系列(state, action)数据对组成的序列,这部分数据提供了聚类算法所需的序列信息。
利用这些特征,我们尝试了不同的聚类参数,并通过将聚类结果压缩到3 维来进行可视化,发现将数据聚成 5 个类别对于我们的数据来说已经足够了。我们通过模仿学习基于每个类别的数据训练了一个模型。通过观察这些模型与强化学习模型对战的过程,我们发现在不同类别的数据上训练出来的模型确实会有不同的战斗模式,例如有的会更喜欢用轻功,而有的则更擅长使用闪避类技能。具体战斗过程可以参见我们报告中的视频。
最后,我们尝试将模仿学习和强化学习结合起来,来修复强化学习AI中的一些不像人的行为。下图展示了一个这样的例子。
在一场战斗开始时,强化学习AI 更喜欢呆在原地等待对手靠近自己,而不是像人类一样逐渐接近对手。需要注意的是,虽然这种行为模式不像人类,但实际上AI学习到这样的策略是合理的。因为如果敌人离强化学习AI很远,敌人也不会伤害到他,从reward的角度来看,留在原地等待敌人靠近是合理的。但是如果敌人被人类玩家控制,看到一个每次开场都一动不动的对手肯定会感觉到比较奇怪。目前处理这种问题的方法一般是引入一条额外的规则来约束强化学习AI,例如“在一场战斗开始时向敌人移动”,这将迫使强化学习AI 与敌人保持适当的距离。但在实践中,这样的规则很容易被玩家利用,从而以一些意想不到的方式击败强化学习AI(另一种可能的方式是通过reward shaping重新训练一个AI,成本会更高并且结果也存在着很高的不确定性)。针对这种情况,我们尝试将模仿学习和强化学习结合在一起来解决这个问题。规则仍然是必要的,我们将规则和强化学习AI结合在一起,然后让其进行多场对战来收集数据。然后,我们会加载强化学习AI并使用模仿学习基于上述数据对其进行微调训练,这一步的目的是教会模型学习该规则。接下来,我们将加载微调模型并使用原始奖励执行额外的强化学习训练过程,这一步的目的是确保规则不会被人类玩家利用。通过这种方法,我们可以修复强化学习 AI 不像人的一些行为,同时尽可能降低其被人类玩家利用的风险。训练结果可以参照我们报告中的视频。
在这个过程中,我们还发现了一些意想不到的有趣结果。下表显示了 AI 在额外强化学习过程之前和之后的规则满足率。从表的第二行可以看出,通过模仿学习微调的模型的规则满足率都非常高。但是在第三行,我们可以看到规则1的满足率大幅下降。规则1的意思是,当对手浮空时,玩家应该施放技能A。我们的专家提供了这个规则,因为技能A会延长对手的浮空时间。但是在强化学习训练之后,我们的 AI 在这种情况下似乎更喜欢技能 B。通过进一步的技能分析,我们发现技能A的施法时间是技能B的两倍。虽然技能A会延长对手的控制时间,但技能B会产生更多的伤害。因此在这种情况下使用技能B有可能是正确的,我们的AI尝试着自行去纠正这个规则。
对于第三条规则,我们的专家认为,当对手被冻结时,玩家应该施放技能C,因为技能C会对被冻结的物体造成双倍伤害。在强化学习训练之后,我们的 AI 仍然保持了这种行为模式。
以上就是我这次分享的全部内容,在我们的工作过程中,越来越发现模仿学习和强化学习是可以互补的,模仿学习除了为强化学习提供预训练模型之外,还有更多非常有潜力的应用场景,当然,也存在着很多困难和挑战等待着我们去解决。在后续的工作中,我们会尝试在更复杂(大型多人战场)、更多样(体育游戏、动作游戏)的游戏场景中验证模仿学习的效果。






 App Store
App Store  Steam
Steam 













 闽公网安备 35020302034348号
闽公网安备 35020302034348号