北京时间7月23日,在游戏开发者大会(GDC2021)上,来自网易雷火UX用户体验中心的数据挖掘工程师Sure进行了精彩的分享,游戏开发者大会每年在旧金山举行,如今已有35届,是一场高质量的大型游戏开发者盛会。
网易雷火UX用户体验中心数据挖掘工程师Sure
Sure于2018年校招进入网易,参与了多款端手游项目的数据挖掘工作,具有丰富的数据挖掘经验,他所在的网易雷火UX用户体验中心是全球知名的一流用户体验团队,业务包含用户研究,大数据研发,体验设计等领域。GDC全球开发者大会二十年来的非赞助类演讲中,雷火UX入围数占中国游戏行业的40%以上,与多所高校建立了密切的合作关系。
大家好,我是来自网易雷火用户体验中心的资深数据挖掘工程师Sure。今天我要带来的主题是大数据方向,题目是“排队:大数据视角下的多人在线开服策略”。
游戏开发者如何在有限服务器资源情况下保证玩家的游戏体验一直是备受关注的问题,设置游戏玩家负载上限是解决该问题的最佳方式,但该方式带来的直接影响就是玩家需要排队登陆服务器,就游戏体验来说排队时间过长或者服务器排队不均会直接导致玩家流失,甚至引起舆论,因此实时动态掌握服务器的排队情况进而调整开服策略至关重要。
因此本议题是站在大数据的视角,基于大型多人在线游戏提出对开服排队情况进行实时监控以及优化策略。议题介绍了多人在线游戏的日志源实时日志获取、解析、优化存储方式到可操作的数据计算,进而实时获得服务器的排队人数和排队玩家的情况。通过玩家信息数据(排队时间、排队服务器等)和玩家游戏内部数据(游戏等级、付费状况、在线时间、任务参与度等等)相结合的方式优化服务器排队,保证老玩家能有一定的优先权。除此之外策略也可以营造排队氛围保持服务器的高热度。
我们会从数据流的角度,结合开服排队案例深入讲解大数据在多人在线开服策略方面的优化。通过本次分享,大家可以了解游戏领域关于日志处理、实时计算以及优化开服策略的方式,并适用到个人或者公司的游戏项目中。
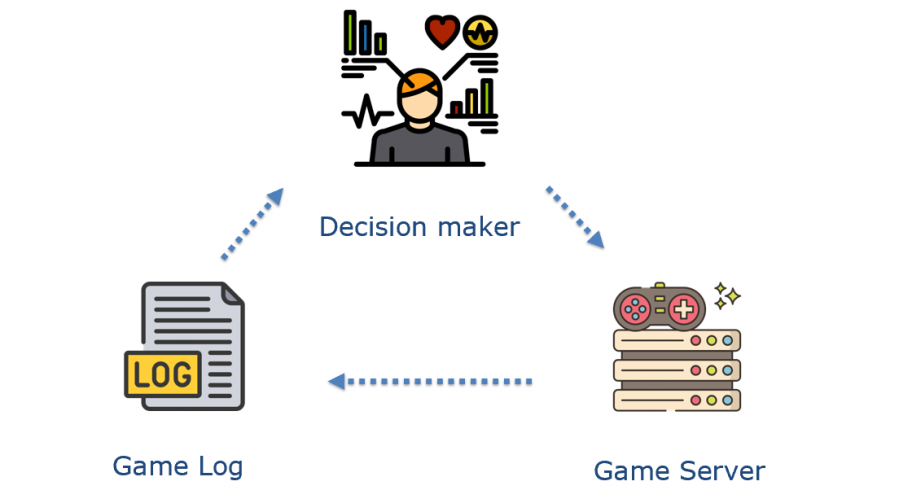
众所周知,很多大型在线游戏在开服的时候都会采用排队方式。排队机制会天然的给玩家带来较差的游戏体验,只能是一种拿时间换资源的权衡方式。既然排队往往是无法避免的,玩家进入服务器前会有等待时间,我们应该尽可能的利用这个时间创造更多价值。为了能够做到上述价值,及时的准确的监控玩家的排队“情绪”是至关重要的。下图展示了游戏中标准的数据流循环。
游戏都会产生日志,通过对日志进行加工做成数据产品比如BI报表,然后使用者通过数据产品能够对游戏状态更加及时准确的掌握,进而优化调整反馈到游戏中,做出更多的操作。游戏优化后继续产生新的日志,因此产生了一种正向的循环,持续的提升游戏。
针对开服策略提出了两种基于大数据的开服策略,分别是“分流”和“导流”方案,前者通过对游戏排队及服务器日志的实时监控,计算各项指标(排队耗时分布、服务器资源等等),判断服务器负载风险,进行及时的开服分流排队。后者方案更倾向于一种全流程的策划运营方案,如打造具备显著特征的服务器,比如社交聊天属性等等,结合玩家游戏画像,引流到策划方案指定的服务器,从而带来更好的游戏体验,两种方案都是建立在优先考虑玩家自主选择的基础上。
分流的开服策略,这也是和常规的开服策略最贴近的一种,目标也是相对简单,就是为服务器分担压力。面对这种开服策略,大数据需要获得信息有两方面,分别是服务器信息和排队信息。如果是遇到服务器压力大的时候最简单的操作就是加服务器。在策略执行的整个过程只需要数据,决策者以及开发人员即可。除了分流的方式,还会有导流的方式。不同于分流的目的,导流是更加面向定制化,旨在打造更加好游戏体验的服务器。想要做到这点,就需要对玩家特征进行获取,这也是不同于分流的地方。在这个过程中参与的角色也比较多,比如数据,开发,决策者,策划,运营等等。
为了能够做到上述策略的执行,需要对数据部分进行分析,分析的数据分为两部分,服务器和玩家。针对游戏玩家,主要分析的有这么几点,首先是排队状态,比如排队时间分布、排队时间玩家分布等等,其次是“是否是老玩家”,通过对老玩家在其他服务器的游戏行为数据进行分析汇总出玩家特征,最后是玩家游戏画像。服务器数据主要是关注服务器的状态,比如服务器在线人数、ACU/PCU、服务器资源等等。
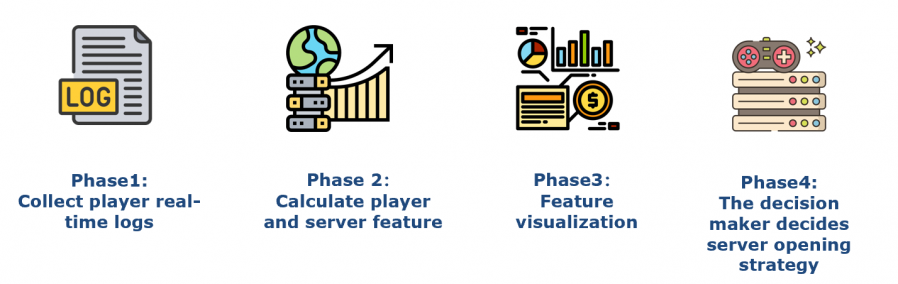
从游戏日志到BI数据产品的标准流程如图所示,首先是收集玩家的游戏日志,根据预先设计的数据指标进行计算玩家和服务器日志数据,接着数据的可视化,最后是决策者使用数据产品进行游戏的策略调整。
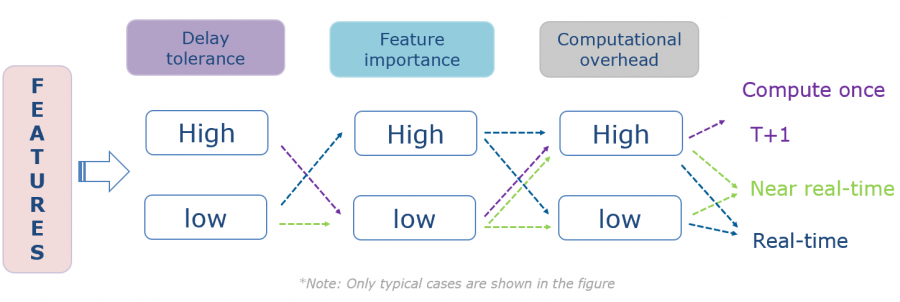
为了做到上述指标的计算,需要考虑的指标特点主要是三个方面,分别是延迟容忍度、特征重要性以及计算开销,根据这三个方面决定使用何种计算方式。
我挑选了一些比较典型的案例,比如紫色线段展示的是高延迟容忍、特征不是很重要,而且计算开销比较大的话就会选择计算一次或者T+1的计算方式。再比如绿色线段,低延迟、特征也不是很重要,那么可以选择近实时的方案,蓝色线段:低延迟容忍,特征很重要,那么就会选择实时计算。
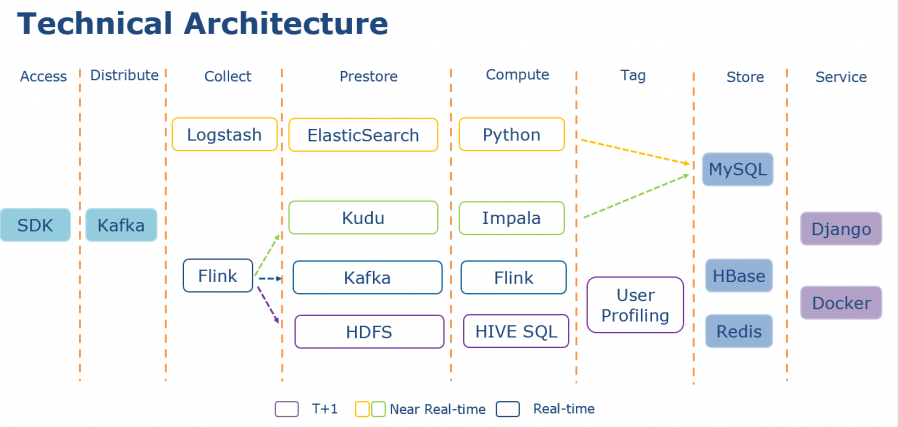
在确立指标计算方式之后,就需要对整个数据计算进行框架设计,如图显示为整个计算架构图。
选用了四种颜色代表了四条技术路线,也可是计算粒度的区别。整个架构拆分为多个层次,其中最为关键部分是Collect、Prestore、Compute、Tag以及Store部分,紫色代表着T+1, 黄色和绿色代表着近实时,以及蓝色代表着实时。T+1计算方式使用Flink收集日志写入HDFS,通过Hive SQL计算数据,最后将计算结果写入Hbase和Redis提供服务。此外,用户画像也采用T+1计算方法。近乎实时的技术路线有两条,一种是使用ELK计算,Logstash收集日志,Elasticsearch存储数据,使用Python计算数据。另一种是结合Kudu,使用Flink收集日志,kudu预存数据,最后Impala计算数据。两条路由都会将计算结果写入MySQL。
最后一种是实时方式,使用Kafka预存数据,Flink进行计算。在服务层,所有方案都会使用 Django和Docker。
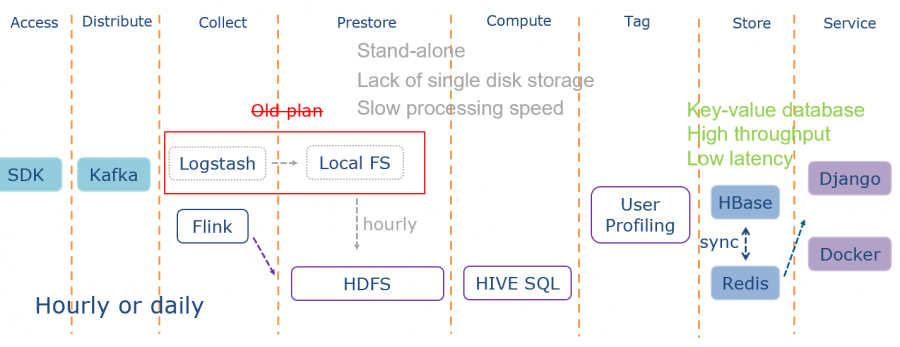
首先介绍的是T+1的方式,在这部分有过两个阶段的实践,在很久之前我们在Collect和Prestore采用 Logstash+Local FS的方式,固定时间周期上传到HDFS上,后来日志量的增多就带来很多瓶颈,比如单机内存不足等等,然后我们引入Flink解决上述瓶颈问题,直接写入到HDFS,采用Hive SQL方式对指标进行计算。考虑到指标的复杂性,在用户画像部分也是采用T+1的方式计算。最终将计算完的指标写入到Hbase和Redis。之所以选择Hbase和Redis是考虑到可以做到高吞吐低延迟的效果。整个过程是小时级或者天级的。T+1方案主要是用来计算低频更新的数据指标。前面提到的用户画像,之所以采用T+1方案,是因为需要计算的指标都相对复杂,也需要数据分析工作,如玩家的聚类和行为分析,最终汇总成玩家的Tag。用户画像日志量大,计算开销也大并且需要人工的参与,因此T+1的方式是最合适的。
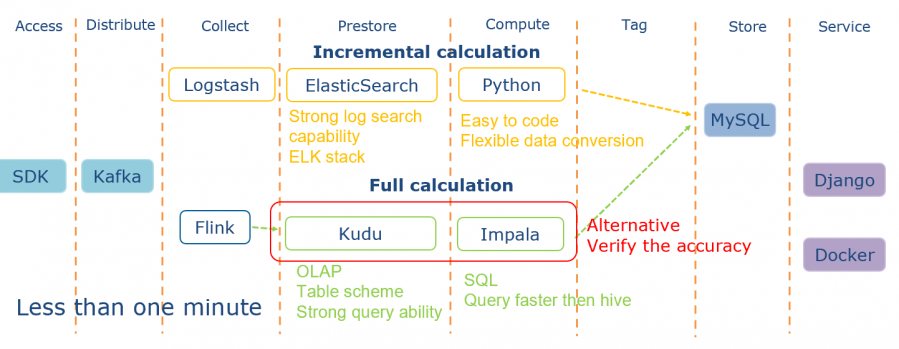
我们在探索近实时的实践过程中保留着两种技术路线,分别是增量计算和全量计算。第一种就是黄色路线所示,利用ES对文本的强大搜索能力进行计算,同时使用Python作为编程语言能够做到快速实现和灵活的数据转化。第二种就是使用Kudu的OLAP能力,同时加上Impala的计算引擎做到数据的近实时计算。第二种因为是全量计算,消耗的资源比较多,通常作为第一种方案的补充,以及第一种方案的数据校验。该方案主要用于计算重要而且复杂的数据指标。
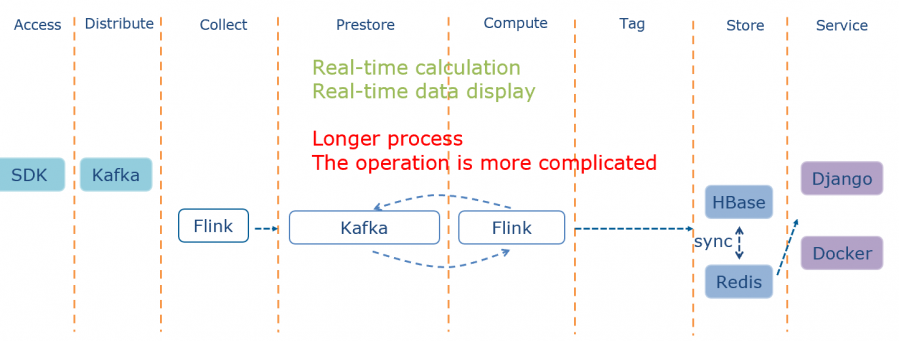
最后就是实时的方案,也就是使用Flink和Kafka对数据进行转化计算,整个过程会更加复杂,依然有着各种优缺点。
在Web服务则是使用了Django、Docker以及K8s,可以做到快速开发,快速迭代,快速部署以及方便拓展。通用开发方案是以近实时为主,实时和T+1为辅的技术方案,做到了计算开销与指标重要度的权衡。
感谢大家,希望能对大家的工作起到一些帮助。






 App Store
App Store  Steam
Steam 








 闽公网安备 35020302034348号
闽公网安备 35020302034348号