北京时间7月23日,在游戏开发者大会(GDC2021)上,来自网易雷火UX用户体验中心的高级数据分析师周壹进行了精彩的分享,游戏开发者大会每年在旧金山举办,如今已有35届,是一场高质量的大型游戏开发者盛会。
网易雷火UX用户体验中心的高级数据分析师周壹
周壹毕业于清华大学,获博士学位,目前是网易雷火UX用户体验中心的高级数据分析师,负责分析游戏数据、研究建模、呈现结果并给出建议。他主要的研究兴趣包括数据挖掘和机器学习,涉及推荐策略、游戏AI等。他专注于在网易的几款游戏中使用数据和算法来改善用户体验,并设计和使用A/B测试平台来验证这些改进与进行更深度的分析。
以下是他本次GDC报告内容的简单总结:
一、背景介绍
在电子游戏中,人工智能(AI)主要用于产生非玩家角色(NPC)的响应性、适应性或智能行为。
在一定程度上,我们希望游戏AI(Game AI)可以表现出类似人类的行为,但更广泛地说,游戏内所有非玩家角色的行为的控制,都可以说是由游戏AI来设计--这意味着游戏AI的目的并不仅仅是模拟人类的行为。
游戏AI的目的在于改善游戏玩家的体验,而不是如“AI”这个词在某些场景下所说的那样力图获得一个通过图灵测试的通用人工智能。
游戏AI在游戏中的应用大致有如下几种:
NPC -- 在传统的RPG游戏里,这类NPC是非常重要的一个部分,他们扮演游戏世界里生活的人们,塑造着世界感,以及提供各种游戏机制,例如商店、任务系统等等。随着游戏技术的进步,我们不仅希望他们作为背景或功能而存在,更希望他们可以仿照游戏所描绘的世界里的人们的正常活动,例如闲时散步、下雨时打伞等等。
敌人 -- 在大量的游戏里,战斗是非常重要的一个部分。相比静态的沙包木桩,玩家显然喜欢更有挑战性、更加聪明、更加多变的敌人。而对敌人、尤其是BOSS的刻画,以及BOSS战斗所带来的震撼感,也成为了游戏设计里越来越重要的一个环节。
队友 -- 无论是单机游戏还是网络游戏,由游戏AI控制的机器人队友始终都是游戏设计的非常重要的部分。在单机游戏里,尤其是网络技术尚有局限的年代,机器人队友给玩家提供了非常重要的陪伴体验;而随着竞技类多人在线游戏的发展,玩家对机器人队友的要求也越来越高。
环境 -- 各种各样的环境互动,当环境,比如小飞虫等等,能对玩家角色和NPC的行为做出互动的环境,能更加提高游戏塑造的世界的生动程度。随着硬件技术的发展,越来越细致的世界描绘也逐渐被引入到游戏工业中来。
可以看到所有的这些机制,都有游戏AI的参与。本质上说,一个生动、活跃、可以根据玩家的不同行为做出不同的反应的游戏世界,能带给玩家良好的体验。需要注意的是上述这种分类方法并不是唯一的,考虑到游戏里需要具备一定的行为、或者说我们需要其表现出一定的“聪明”的物体是如此之多,游戏AI包含的含义是非常广泛的。
当前,随着网络技术和硬件技术、包括移动端设备和移动互联网的发展,多人在线游戏正成为更多玩家的选择。在这里面,游戏AI也发挥着重要的作用。
在多人匹配的在线游戏里,当新手玩家进入游戏时,如果直接把他们和熟练玩家进行匹配,往往导致这批玩家的体验不佳。虽然可以通过以游戏技术匹配的方式来解决一部分问题,但也可能造成新手玩家等待时间过长等负面体验。而通过游戏AI驱动的机器人(Bots),可以调整游戏节奏和难度等级,顺滑玩家的体验,令玩家获得成就感,避免尚未熟悉游戏导致的挫折流失。并且可以通过设计好的游戏机器人,提供体验顺滑的新手教程,令玩家的训练和匹配无缝衔接。
同时,对于各个等级段的玩家,机器人都可以在匹配时间上起到调节作用,提供队友或者匹配对手,提升玩家的长期游戏体验。
当然,现在很多多人在线游戏也具有单人剧情模式或者组队PVE模式,在这种情况下,游戏机器人和传统的单人游戏里那样,发挥了扮演队友、敌人的作用。
二、游戏AI的实现方式
从机器人是否基于游戏产品设计者编写的确定规则来区分,可以分为静态机器人和动态机器人。
其中,静态机器人,基于确定的程序规则实现,历史非常久远,在工业界有大量而广泛的应用。静态游戏机器人需要很多帮助才能适当地采取行动,它们的存在通常是为了提供线性功能。
而动态游戏机器人,基于机器学习与人工智能的法实现,可以参与学习关卡布局、学习新策略等。当前相关的演示和成果非常多,也是学术界的热点,有一些基于星际争霸、Dota的非常著名的前沿探索,展现了非常强大的潜力。这些机器人在一些游戏里已经有了应用。
1、静态机器人 - 有限状态机
实现静态的机器人,主要有两种方案:有限状态机和行为树。
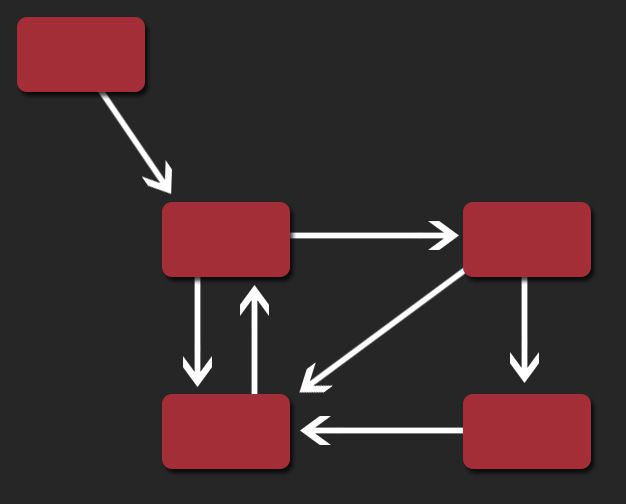
有限状态机的原理示意图
有限状态自动机 (Finite State Machine,FSM)是表示有限多个状态以及在这些状态(State)之间转移(Transition)和动作(Action)的数学模型。有限状态机的模型体现了两点:
一个有限状态机是一个模型,具有有限数量的状态。它可以在任何给定时间根据输入进行操作,使得系统从一个状态转换到另一个状态,或者是一个输出或者一种行为,一个有限状态机在任何瞬间只能处于一种状态。
并且,其状态是离散的:某一时刻只能处于某种状态之下,且需要满足某种条件才能从一种状态转移到另一种状态。
这样,这个模型,通过状态机这个对象状态的管理器,就可以实现对象在满足某些特定条件后在不同状态之下的转换,并且可以根据定义好的规则,在不同的状态下产生不同的行为、具有不同的属性。
有限状态机的应用范围非常广泛,尤其是在游戏领域。各种各样的游戏内的活动对象都可以通过有限状态机来驱动。
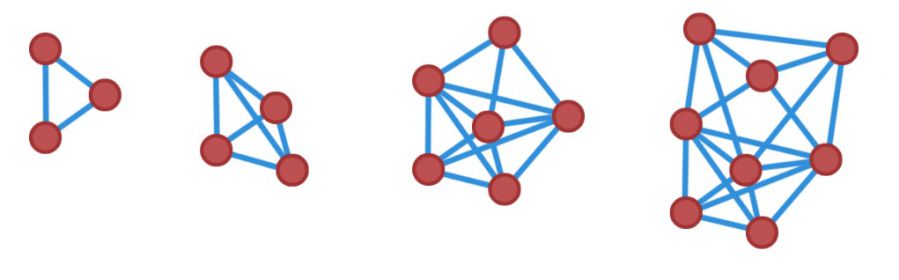
但是,尽管有限状态机在实现原理上非常便于理解从而使得它可以很好地完成一些较为简单的游戏AI任务,但是,在面对较为复杂的AI逻辑需求时,这种方案就会越来越显出其过于繁琐的缺点。除了系统的可读性会成倍下降之外,当需要对现有AI的逻辑进行扩展的时候,就会发现要维护的状态量会极快地增加--每多加一个状态,则需要增加几条转换线,越多状态,需要增加的转换线越多。
有限状态机的复杂度随着状态数增多而陡增
总体来说,有限状态机在应用中的问题是:各个状态类之间互相依赖很严重,耦合度很高;结构不灵活,可扩展性不高,难以脚本化/可视化。
在以前,游戏AI的实现基本都是有限状态机,而随着游戏的进步,游戏AI的复杂性要求越来越高,传统的有限状态机实现很难维护越来越复杂的AI需求。
分层状态机一定程度上缓解了这个问题,但并没有彻底解决。而且随着状态的增加,各个层也会出现上述的困难。也由于这个原因,比较多的开发者投入了行为树的怀抱。
2、静态机器人 - 行为树
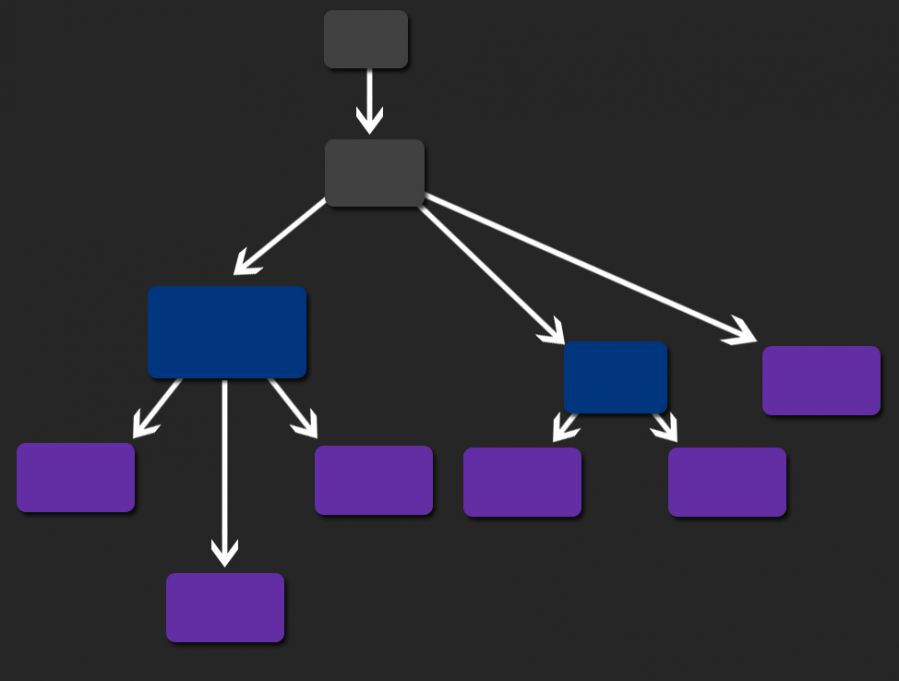
行为树(Behavior Tree,BT)模型是由行为节点组成的树状结构,通过类似于决策树的树形结构,来让AI可以根据当前所处的环境来选择出应该做出的行为。
不同于前面提及的限状态机或其他用于 AI 编程的系统,行为树使用树结构来控制 AI 决策行为。这种结构包含了各个类型、各个层级的节点,节点的最末端是叶子节点,也即是最终 AI 执行的行为或者输出的状态。而各个节点间的连接和这些中间节点的特性,决定了 AI 的逻辑的实现方式--即如何从树的顶端,根据当前所处于的不同的状况和环境,沿着各种路径最终来到确定的末端叶节点并输出行为的过程。
行为树方案在游戏AI实现的有很明显的优点,其可读性、条实行、复用性都很强,这使得它逐渐成为当前游戏领域的较为主流的AI实现方案。
行为树的原理示意图
很多游戏引擎都自带这个功能。如unreal和unity,都具有很多行为树相关的开发工具和扩展插件。
行为树可以通过一层一层的树结构向下延伸,这种延伸具有可迭代性。大型项目中,可以建立行为树库,通过各种逻辑的连接来实现非常复杂、能够在不同场景下做出有深度的行为、且具有复用性的游戏AI。
由此可见,行为树的主要优势之一就是其封装性、模块性和扩展性,配合各种优秀的开发工具,可以让游戏AI的逻辑实现更加直观,而不用想有限状态机那样面对一个庞杂的网状结构。
当然,使用行为树进行游戏AI的开发,在初期会比有限状态机能需要一些技巧。后者可以直接进行状态的罗列定义以及设计转移条件,而前者需要在一开始就设计好一个更为全面的树形结构框架,来把游戏AI所面临的各种情况抽象为各种类型的节点。虽然在抽象逻辑的时候需要技巧,尤其是在项目预计比较复杂的时候,但后续的维护、可读性都很高,对于复杂项目而言这种优势是巨大的。
总的来说,行为树在复杂的情况比有限状态机更清晰,更可拓展,行为树有利于逻辑的重用。并且当前已经有很多可视化模块工具便于设计师使用,使得行为树方案具有很高的可读性,也便于调整,熟练之后设计的效率会很高。
3、动态机器人 - 强化学习
上述传统的游戏AI实现方式,基于规则驱动,来用人为定义好的条件来触发预先设计好的游戏行为。一个直接的表现就是,人为设计投入的力量越多,模型的条件越多,产出的行为就会越复杂,游戏角色就会相应的更加“智能”。
但用这种方案实现复杂AI时,对于人力的需求往往过大,并且现实中总是不可能以规则覆盖所有的情况,而使得游戏机器人或多或少在某些情况下显得机械而呆板。
针对这些问题,以强化学习为代表的人工智能技术展现出了非常强大的潜力。原理上说,当我们把游戏状态作为输入,把游戏AI的行为作为输出,那么就可以构建一个典型的神经网络模型,如此,便可以通过训练的方式摆脱对人工设计好的规则驱动的依赖,来通过模型的自我训练获得一个更加聪明、更加全面的机器人。
越来越多的游戏宣称他们使用神经网络等方法来提高游戏AI,使得更有挑战性,这里面包含大型游戏也包含小巧精致的卡牌游戏。
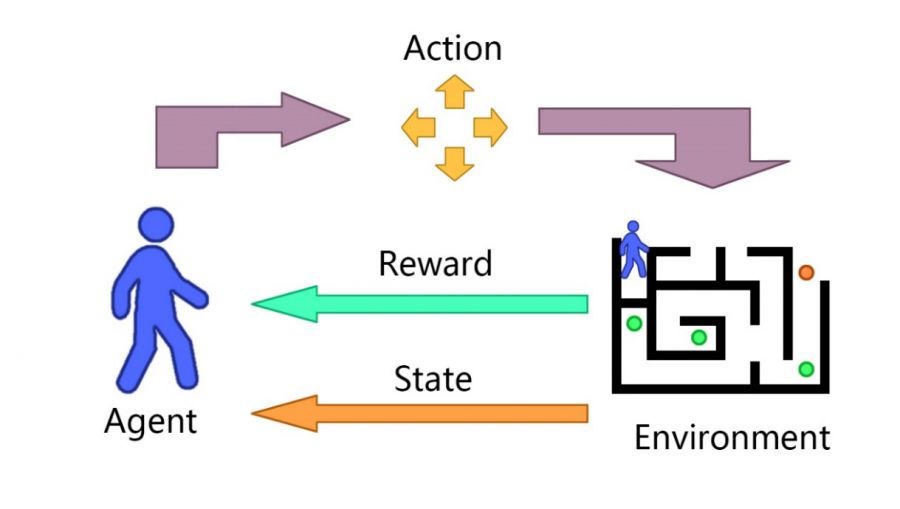
强化学习是机器学习领域的一类学习问题,它与常见的有监督学习、无监督学习等的最大不同之处在于,它是通过与环境之间的交互和反馈来学习的。
它关注的是软件代理如何在一个环境中采取行动以便最大化某种累积的回报。正如一个初学的棋手,它通过试探各个位置的下子来对环境--这里指他的对手的反击--进行探索,并且慢慢地积累起对于环境的感知,通过和不同的对手一盘一盘得对弈,慢慢积累起来我们对于每一步落子的判断,从而慢慢地提高自身的围棋水平。
AlphaGo围棋程序在训练学习的过程中就用到了强化学习的技术,还有dota2的Open AI,星际2的AlphaStar。
强化学习的基本模型,就是个体与环境的交互,并在交互过程中,训练使得个体可以采取的策略让其获得最大的奖励--不仅仅是当前这一次行动对应的奖励(也就是说,并不是贪心算法),而是长期角度的最大奖励。而能够获得这个最大奖励的个体所采取的行为方案,就是强化学习的目标结果,即策略。
强化学习的原理示意图
可以看到,和传统的监督学习或非监督学习不同,强化学习任务依赖于不断和环境交互并得到反馈,这对于传统的预先收集的数据集来说往往是不现实的,比如,对于复杂一些的任务,我们不可能预先把所有的个体可能面对的环境的可能与采取的可能的行动与对应的奖励记录在数据中然后用以训练模型。也就是而很多现实的环境下强化学习的应用会受限于标注的数据集--总体上其反馈信息是较为稀疏的。
而游戏AI,则是强化学习的一个非常完美的平台,基于程序实现的游戏流程,可以通过个体间的自我对局,快速产生海量的训练数据,并能够极快地实施测试与记录。而游戏AI的任务目标也与强化学习的模型特性高度契合。这种可行性与价值上的意义,使得强化学习在一段时间内涌现了大量的成果。
但现实世界的游戏AI里,强化学习的应用也并非如模型本身那样简单,具体的应用中存在这样的几个问题:
首先,强化学习的奖励函数并不好设计。有些机制复杂的游戏,奖励函数的设计非常困难,且比较依赖主观判断,又缺少一种绝对的评判标准。固然在棋牌类游戏下,可以用最终的胜负来作为目标,但实际的多人在线游戏里,机器人的胜率不代表游戏工业对机器人的需求。可以这么问:玩家是否真的希望AI非常强大?体验和胜率能否划等号?事实上目前的游戏里,尤其是PVE内容里,还有大量的时间轴和简单行为触发的敌人,对这样的场景,似乎玩家并不希望敌人过于智能。
同时,复杂的游戏机制会带来很高的模型复杂度。例如说,很多游戏因为战争迷雾、观察视野、手牌互相不可见等因素,所有游戏参与者都只能获得一部分信息;同时,不少游戏存在非常普遍地随机性的影响,典型如同有抽牌因素的很多卡牌游戏,这些都对强化学习模型在工程中的应用提出了更高的要求。
并且,因为计算空间的过于庞大,这导致在有限的资源内,容易陷入局部最优而产出平庸方案。比如纯粹依赖强化学习互相博弈来训练的机器人,很容易得出一种人类看来非常愚蠢、呆板,但又可以起到一定作用的粗暴策略。这个问题一方面通过加大计算资源来解决,另一方面可以结合有监督学习解决一部分问题。当然这需要标签数据,也即是人类的游戏行为,这又增加了数据获取、数据处理的难度。
三、关于卡牌游戏AI
当前,随着用户时间碎片化的加剧和移动端设备和互联网性能的提升,在移动端的、单局游戏时间较短的多人在线卡牌游戏的市场份额也在不断提升。
这类游戏的核心玩法非常统一,即进行卡牌对战。这样,玩家的牌局体验就对于产品的留存与收入至关重要。而在现实的产品运营中,基于各种考虑,机器人牌手总是这类卡牌游戏的一个非常重要的组成部分。它可以用来解决类似于冷门时段内匹配时间过长,新手玩家因为水平层次较低而体验差等一系列问题。
卡牌游戏因为其本身的特性,玩家的状态显然是离散的,相对动作类游戏、RTS游戏来说,当前的状态更容易被精确描述。同时,因为其回合制的特点,使得游戏里各个玩家的行为更加的容易被描述和记录。这一些使得卡牌游戏是研究游戏AI的非常好的平台,可以更接近AI的本质。
同时,卡牌类游戏普遍节奏较快,信息也更容易获取,有些流行的游戏拥有非常庞大的在线玩家,可以提供海量的数据。并且,对于快节奏的靠游戏来说,玩家和Agent做出的行为也更容易做出直观的解释。这对于研究AI是有利的。
并且,卡牌游戏中,AI和人类进行的是公平的、纯粹的决策博弈。这一点非常重要。典型如RTS游戏的AI训练中,人类玩家显然存在各种生理限制,比如每秒钟的点击次数、屏幕切换的最小所需观察时间等等。而机器人选手则没有这样的限制,但如果机器人被允许每秒钟点击上万次,或者每秒钟可以切换屏幕上百次观察所有细节,那么显然是不公平的,基于这样的设置训练出的AI可能并没有、也不需要任何高明的战略,而仅需要强大的单位操作就可以击败一切人类选手。这样就完全偏离了研究的本意。所以当前的这类项目都会对AI的能力做出限制,但这种限制需要考虑的方面太多,并且人类选手的水平也存在巨大的层次差异,这使得在这类游戏里,如何限制AI能力并不是一个可以被彻底论证的事情。
而卡牌游戏的模型则非常纯粹,也同样有利于研究AI。
最后,大量的在线卡牌游戏的产品,和卡牌游戏本身相对简单的交互机制,使得这类型的AI成果较容易被实际应用,卡牌类游戏的大用户基数也使得其AI的应用更容易被验证成果。
如前所述,卡牌类游戏中,因为状态是离散的,加之存在回合的机制,玩家和机器人往往是交替出牌,那么相比其他游戏,在卡牌游戏中玩家更容易感受到局势,更容易感受到机器人的策略的细节。
并且,玩家也会对机器人的行为有更高的要求。比如,机器人作为敌人时,如果在明明可以取胜的情况下没有击败玩家,或者在作为队友时做出失误导致队伍遭受损失,这类情况在即时的、观察受限的FPS游戏或者动作类游戏里,往往不为玩家所知,或者被玩家归结为偶然因素或者说好运气、坏运气。但在非常容易观察到局势细节和机器人动作细节的卡牌游戏里,则会令玩家感受到很明显的不良体验。
同时,虽然卡牌游戏的状态相对来说比较容易描述,但因为有强烈的随机因素--最典型的就是抽牌--深入介入了游戏机制,甚至在很大程度上决定了一局游戏的胜负。这样强烈而决定性很强的随机因素使得卡牌游戏的强化学习模型也并不是很容易训练。
最终,卡牌游戏里的,comb是一个非常重要的组成部分。通过各种战术,形成特定的局面,使用一系列特定的卡牌的特殊效果,实现较为复杂而强大的效果,一直是卡牌游戏里玩家体验的一个重要组成部分。而这就对卡牌机器人的训练提出了非常高的要求。因为在大量的卡牌组合下,仅有特定的若干组合能够形成comb,并且其使用的时机也非常讲究。这就使得单纯要训练出这种行为需要极其庞大的计算资源,否则机器人只会更倾向于使用简单粗暴的战术。
当前,通过卡牌游戏研究AI已经成为一个热门的领域,很多的论文工作都以当前的流行卡牌游戏为例进行了强化学习或其他人工智能项目的探索。
四、讨论与思考
很多学术界的成果都在探讨如何训练与提高Agent,强大的技术发展也产出了很多瞩目的成果。但这里,我们需要回过头看一下这个本质的问题:为什么我们需要机器人?
对于具体的游戏产品而非抽象的学术研究来说,这个当然应该从玩家体验出发去看待。
但是,玩家喜欢什么样的体验?这并不是一个容易回答的问题。
比如说,玩家某些情况下需要掌控感,某些情况下需要惊喜,更多时候是两者都需要。对于某些游戏来说,玩家其实更期待机器人队友的表现是可以预期的,即使其表现并不高明。玩家会习惯与把机器人的逻辑特点纳入自己的战术体系之中,来决定自己的行为。此时机器人如果表现的过于多变、尽管可能更符合人类的行为,但可能并不是玩家乐意看到的。
同时,玩家的体验也需要在挑战性和成就感之间寻求平衡。过于机械简单的敌人会令玩家的游戏过程非常枯燥,但过于强大的敌人也可能使得玩家在反复失败之后快速流失。
尤其是还存在一种情况,新手玩家被过于高明的机器人击败后,可能并不能感受到机器人的策略的强大,这样不仅无法借此提升自己的技术,甚至可能误以为是机器人设计了不平衡的游戏机制,从而带来非常不良的体验。
本质上说,和学术上不同,实际游戏产品的机器人最终的目的并不是追求最高的胜率,而是提高玩家的游戏体验。而在某些情况下,这个目标是与拟真或者博弈强度是相悖的。
实际的训练过程中,这些困难导致强化学习模型在学术上那些成功案例里所体现的巨大优势(通过大量自我对弈快速产生海量标签数据)被削弱了,因为agents的自我对局固然可以很方便定义胜负,但却不能代替我们回答怎样的游戏体验更好的这个问题。解决以上这些困难需要花费大量的时间和精力,需要有对玩家行为和游戏机制的非常深层次的理解。
这也说明了,算法的前沿进展,可以在游戏工业中发挥重大的价值,但也必须和深入的用户行为研究结合起来。






 App Store
App Store  Steam
Steam 








 闽公网安备 35020302034348号
闽公网安备 35020302034348号