北京时间7月23日,在游戏开发者大会(GDC2021)上,来自网易雷火UX用户体验中心的数据挖掘工程师Chalet和数据产品经理泽臣一同进行了精彩的分享,游戏开发者大会每年在旧金山举办,如今已有35届,是一场高质量的大型游戏开发者盛会。
Chalet
泽臣
Chalet是和泽臣分别于15年、17年进入网易,他们所供职的网易雷火UX用户体验中心是全球知名的一流用户体验团队,业务包含用户研究,大数据开发,体验设计等领域。GDC 全球游戏开发者大会二十年来的非赞助类演讲中,雷火UX入围数占据中国游戏行业的40%以上,与多所高校建立了密切的合作关系。
这次分享,两位演讲人将会从管理架构和开发管线两个方向进行介绍,给需要打造敏捷数据团队的游戏开发商提供了一个可行的方案。以下是分享的实录:
泽臣:大家好,感谢大家来听我的本次分享,欢迎我会跟大家介绍一下数据团队将会面对怎样的数据需求,了解你的需求者制定合适的服务计划,以及如何做好需求管理。Chalet,他会注重技术方面,告诉大家数据服务的流程是怎么建立的,以及如何保证全链路的数据质量保证。
数据团队是什么,他们提供的是什么样的服务?首先我们需要明白,数据团队作为中台部门,会同时服务多个游戏开发团队,并未他们提供基于游戏数据的分服务。通常情况下,我们认为的数据团队服务内容就是为产品提供符合要求的数据(值),以及相应数值的可视化。这些数值可能是过去的结论,也可能是正在进行中的实时数据,也可能是基于前两者产生的对未来的预测。当然我们也会提供基于数据的衍生服务,比如开发基于数据的产品工具,帮助产品更好的完成游戏设计。
数据团队会同时为多个团队提供数据支持
BI平台,相信的大家都见过,这是一个用作监测核心业务状态的可视化工具,雷火UX研发了一套属于自己的数据平台,我们称之为“天眼”,不使用第三方的服务主要是出于成本和自定义程度的原因。数据看板是一个自助的数据展示平台,能为使用者解决两个最根本的问题,我的游戏怎么样了,我应该在运营上进行怎样的调整。
BI平台最直接的价值在于为用户提供现状的查看入口,包括但不限于实时或T+1的数据、环比或同比数据。此外,也可以通过长期的数据收集,为用户提供整体趋势情况以及通过定义目标,在数据看板中实时监控目标偏离情况。BI平台可以集成底层的基础信息,同时也可以根据业务属性、业务需求,通过基础信息进行管理指标的计算和管控。它是一个非常有效的数据工具,因为他能覆盖到从普通设计者到决策者所有的游戏开发者。只要通过权限控制,就能进行核心数据的展示。这极大程度上降低了数据团队的人力支出。
对比BI平台,数据挖掘的需求更多的是单次不需要持续查看的需求,以验证性目标为主。
数据挖掘的特点是能完成高度自定义,基本上任何数据需求都能被我们的数据挖掘工程师计算出来。另一个特点是是实时性,出于性价比考虑,BI平台的实时性一般都比较差(不是无法做实时性,只是很多数据实时化价值不高)。而数据挖掘就可以完成实时性的拉取,对于敏捷需求的响应会更加快捷。不过它的缺点也很明显,进行数据挖掘将占用开发人员很多的开发时间,本质上数据挖掘是重复的低创意性劳动,对于开发人员本身来说都是一件容易疲劳的差事。另外,如果是需要频繁查看的数据,也不太适合直接机械能数据挖掘,数据看板会更加合适。
所以我们遇到了一个比较尴尬的情况,我们希望解放开发人力,不做低价值的数据挖掘,我们又希望能够给需求者提供非常定制化的数据结果。于是我们找到了一个解决方案。一个不需要数据挖掘技术的数据挖掘系统,或者是使用自然语言的数据挖掘系统。它能实现绝大数需求的自定义查询,而使用者不需要任何程序基础,任何都可以来进行挖掘。我们会事先处理好数据日志(都是自动化的)。然后用户可以利用一个平台直接查询。不过在初期我们遇到了一个棘手的问题,如何把大家需求转化成查询条件,不是每个人都有缜密的数据逻辑思维。最后我们尝试将自然语言的表达逻辑进行拆分,尽可能的通过几步的填写就能完成策划脑中的需求转化为计算机能理解的SQL语言。
如果面对复杂的数据需求,简单的数据无法很好解答的情况下,我们需要怎么做呢?这个时候,就需要数据分析工程师了。简单的数据他能代替产品进行分析,同时不需要数据挖掘工程是支持。,通过自己的游戏认知设定数据挖掘方案,用挖掘的数据来佐证自己的猜想。总的来说,数据分析员可以实现数据挖掘和数据分析的自循环。
同样,不同的游戏开发团队有着不同的数据需求,我们可以简单地把他们分为“专家型”,“领主型”,“婴儿型”。
“专家型”团队是最受欢迎的开发团队,他们能够清晰地了解数据的重要性,并给与准确的数据需求目标。会事先准备所有数据开发的资源,如日志等。通常这些开发团队与数据团队有过多次合作经验,开发团队负责人认可数据价值,希望能够用数据驱动产品迭代,游戏设计会以数据驱动的方式。
“领主型”团队可能知道数据的额重要性,但是并不会主动提出数据需求,通常在需要的时候才会提出需求,往往对时效性要求很高,经常临时提需求,不愿意花时间对于数据进行沟通,但又想看到分析结果,开发团队人力紧张,无法应付数据日志的优化需求。
而“婴儿型”团队基本不知道游戏数据对于游戏研发的价值,基本不会专门为游戏数据提供实现的准备。一般来说一个崭新的游戏开发团队容易遇到这样的问题。
不同的团队对于数据的价值判断,以及如何利用游戏数据指导游戏研发是不一样的。作为数据中台部门需要提前做好准备。“专家型”的团队对于数据需求很明确,我们需要提供个性化的数据获取方案,比如之前提到的一些自助获取数据的平台工具。提升团队对于数据的利用率。面对“领主型”的团队,最重要的一点还是提前沟通,及时预警。将常规的需求及时确认和准备好,并做好数据监控,一旦发现异常尽早和产品团队进行沟通,从而增加业务的支持效率。而最后的“婴儿型”团队,提前的数据意识培养非常重要,我们会排除数据产品经理为产品进行产品功能讲解,梳理需求规范,以及商讨后续的工作流程。
我们对接了各种各样的团队,那么我们需要怎么进行管理呢?
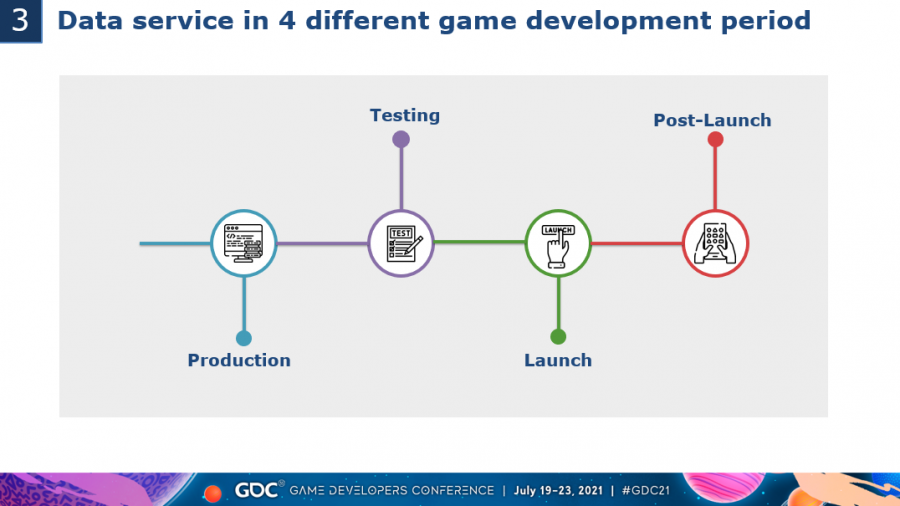
我们把数据需求的服务时间段分为4个主要的阶段。通常数据需求会在研发期就出现,在测试期需求逐渐变多,在游戏刚上线阶段达到顶峰,等到稳定运营期又逐渐降低
产品的不同阶段需要有不同的数据服务策略
在研发期,数据团队能提供的支持很有限。因为往往这个时候游戏还处在α阶段,设计还不是很稳定,没有大量的玩家数据。不过这个时候也是和产品服务最关键的时间点,因为一切的数据来源都是游戏中的日志,所以日志的质量决定了一切后期服务的准确性。我们通常会给产品一份日志标准开发文档,指导他们进行日志打点。并提供一个自主的日志校验工具,帮助他们测试打完的日志是否存在格式问题。完成日志打点确认后,就需要跟产品约定BI系统的开发内容了,因为这往往是在对外测试需要用到的功能
到了对外测试期,大量的玩家涌入制造了了大量的日志。这是给数据服务的第一个挑战,所有的日志问题都会在这个阶段暴露出来。 另外BI业务也会面临第一次实际考验,在这阶段,页面的访问频率会比较高。不过好在因为只是测试,所以在结束后依然有很多的时间数据分析和数据挖掘工作,所以对需求的实时性要求不是很大。
上线初期是最大压力的时期,这个阶段产品往往也是最关注游戏中的数据表现。同时刚上线时期的玩家量级也几乎是整个游戏生命周期中最高的一段时间,日志量也非常的大。同样对于数据挖掘和分析结论都有很高的效率要求,毕竟产品需要用来做快速的线上调整。
当游戏进入稳定期后,大部分的需求都变成周版本的形式展开,因为产品会有一个比极高稳定的运营计划,需求提出的时候也会留出提前量,让团队成员有足够的时间和精力进行准备。这个阶段,我们可以尝试提供基于数据的额外服务,帮助产品提升运营情况。
Chalet:泽臣从业务和需求的角度详细介绍了数据团队如何管理的问题,我将从另一个角度,也就是数据开发的角度来重新阐述这些问题。如何从头建立一支游戏数据团队,首先我们需要了解基本的数据管线,然后配置相应的开发资源。
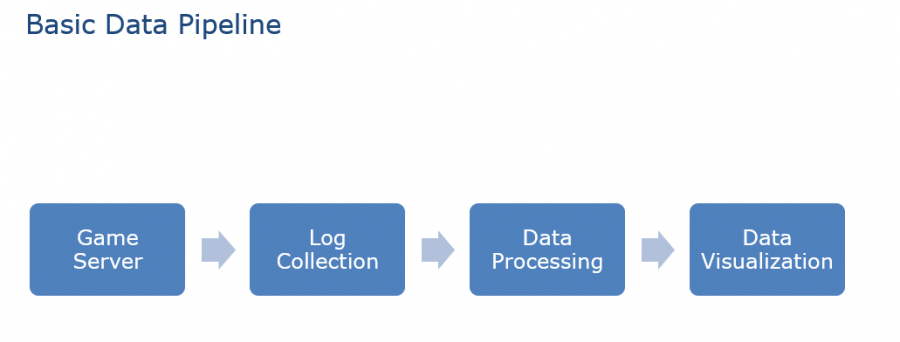
一条基本的数据管线是从游戏服务器开始到日志收集、日志处理,最终到数据可视化的阶段,而离线和实时开发只是各自使用工具的不同。离线大数据系统跟Hadoop系统是没法分开的,一个基础的大数据系统离不开HDFS的存储和MapReduce的数据处理,这个离线系统非常的健壮,除了存储和处理的过程有点慢,当我们需要及时处理数据的时候,这个系统就难以实现这个目标了。对于实时的数据处理系统,我们这里使用了2个工具,分别叫Kafka和Flink,对应的工作分别是日志收集和日志处理,我们可以注意一下,这里收集和处理不仅仅是日志,而是日志流。如果对这个主题比较感兴趣的话,可以去看一下我们去年在GDC上发表在Online Game Technology Summit上的演讲,演讲的题目叫做 《Real-Time Data Processing for Multiplayer Online Games》。
我们在同一条数据管线上面呈现了两种数据处理模式,不过我们都是假设在处理一款游戏的数据上。当游戏团队开发了很多款游戏之后,数据管线会变得更复杂一些。
第一件遇到的问题就是日志的记录方式,不同的游戏会有不同的记录方式,比如玩家在登录界面登录游戏这个简单的操作,但是在最早的时候,不同的游戏团队可能有不同的记录方式,有的叫Login,另一个也叫login,但是纪录成小写的,还有的叫LoginRole或者logon。
为了解决这种日志记录混乱的情况,我们制定了统一的日志标准,概括起来就是,所有的日志都必须记录成统一的格式,而且表示相同事件含义的日志,字段结构必须保持一致性。
所有的日志在游戏中都使用如下的记录方式,从左到右分别是日志时间、日志名称和JSON格式的日志内容,另一件重要的事情就是不同游戏中的相同事件记录成相同的字段,以OnlineRoleNum为例,当记录玩家在线人数的时候,始终使用相同的日志名称和相同的JSON字段。
除此之外,不同的游戏团队可能会选择不同的日志传输方式,让数据管理变得十分棘手。我们的策略是所有的游戏使用相同的工具收集日志,然后统一传输到Kafka集群里面,但是不同游戏的日志传输到不同的topic里面。通过这样的设计,我们可以构建一个统一的日志传输系统,为统一的数据处理流程提供支持。
最后,到了数据可视化的部分,开发数据报表给游戏产品方使用。目前有一些商业的BI软件可以使用,但是对于游戏业务不够定制化和灵活。为此我们开发了一个low-code的BI系统,通过简单的配置文件就能实现数据可视化。除了常规的数据可视化方式以外,我们的系统还可以做一些更有趣的事情,比如开发一个热力图,可以在游戏真实的地图上面实时显示玩家的死亡情况。对于商业的可视化系统来说,是很难支持如此定制化的需求的。
如果只是做到这些,系统还不够智能化和自动化,我们最终的目标是希望游戏策划可以自己查询他们想要的数据。假如现在有一个游戏策划,他有这样一个需求:我想知道上个版本买了A道具的玩家有多少买了这次版本的B道具。对于这样的需求,我们可以使用一些自然语言处理的技术将其解析成后台的SQL查询,最后将这些查询发送到一个ad-hoc的查询系统中去。我们为什么需要一个ad-hoc的查询系统,因为被解析的SQL是无法提前预知的,而且在解析成SQL查询之后,系统需要几秒之内就要返回结果。
开源社区有很多查询引擎可供选择,这里我们列上了目前最流行的一些查询引擎。对于这些查询引擎来说,查询时延跟对SQL JOIN语句的支持情况是我们项目中最重要的考虑点。所以,对于一个自助的BI系统来说,Druid不是一个良好的选择,因为不支持JOIN,导致无法支持很多复杂的查询。在实践中,Impala和Presto是更好的选择,尽管他们不是目前最快的查询引擎。
最后一个部分,我们将介绍如何对数据管线做质量保障。想象这样一个场景,当游戏制作人得到一个关于游戏新增和留存的错误数字,可想而知,后果是十分严重的,可能导致游戏产品团队对数据团队丧失了信任。我们回忆一下整个数据管线的内容,从管线的开头到结尾,我们可能遇到的问题有这么几个,首先是原始日志记录就有问题,这种影响最大,因为在整个数据管线的最开头,对后续所有的环节都会产生影响,而且问题还比较隐蔽。第二就是日志传输出了问题,这种是比较容易监控和定位问题的,只要把数据链路排查一遍就好了,最直接的办法就是从Kafka之中获取最新的数据流,统计每分钟日志的记录数,一旦数字出现异常可以随时发出警告。对于数据处理这一环节来说,最常出现的问题,就是程序员写了一些bugs出来,尤其是团队里面成员水平参差不齐的时候。最后, 我们仍然需要对最终产出的数据结果制定一些检验规则出来,作为我们最后的保障,当出现异常的结果时,可以随时回到数据管线上面来,仔细排查每一个环节是否出现问题。
就日志中出现的问题,我们团队遇到过很多,比如IP地址纪录成内网的,海外发行的时候没有记录币种的或者漏记了时区的信息。为了解决日志可能出现的问题,我们开发了一个日志校验的工具。游戏开发和QA在拿到服务器日志之后,输入样例,输出日志中不规范的地方,并且提供正确的样例供参考。
对于数据处理阶段,如何避免程序员写出bug的问题,我们的做法是提高复用性和标准性。通过设计标准的日志格式和内容,并同时设计标准的结果产出,这样我们可以把数据处理过程变成一个黑盒,数据开发者不需要关心这里面的技术细节,从而规避bug的产生。
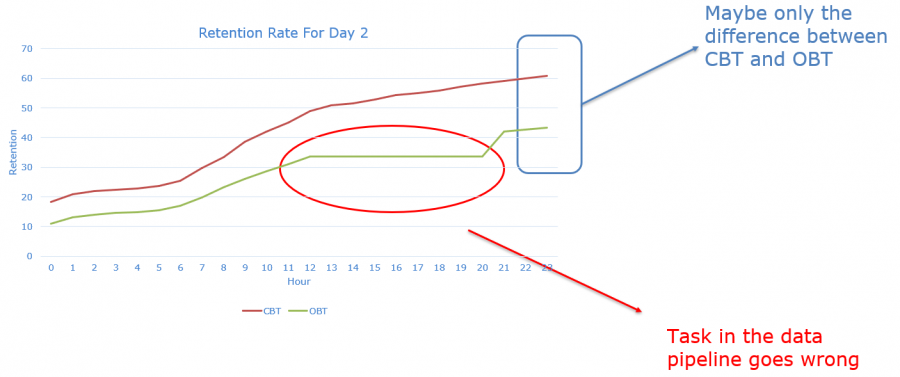
最后,永远不要忘记去直接检查数据结果,即使前面的环节做得再完美。这里有一个例子,同一款游戏在CBT和OBT阶段的次日留存,这一条直线说明整个数据管线是一定有异常的,但是CBT的结果一直比OBT高可能只是不同测试阶段的差异。CBT阶段通常需要激活码,而且吸引的往往都是游戏的核心玩家,但是对于OBT来说,并没有玩家数量上的限制,什么类型的玩家都会来尝试一下。所以在CBT阶段我们更可能遇到游戏的核心玩家,核心玩家的留存更好也是比较理所当然的事情了。
通过本次分享,大家可以了解到如何给不同的产品团队成员提供不同的服务,如何通过一个自动化的系统来减少人力投入,提高数据团队服务的价值和效率,去了解如何构建一条数据管线以及如何为数据管线做质量监控。






 App Store
App Store  Steam
Steam 















 闽公网安备 35020302034348号
闽公网安备 35020302034348号